
In today’s era, the rapid development of big data technology has brought about a great impact on the personnel management model. Traditional personnel management often relies on manual operation of industry judgment, often the problem of incomplete information and processing inefficiency, affecting the management of employee information, so the introduction of big data technology into the personnel management system to improve the accuracy and efficiency of information management [2]. Talent recruitment is a key part of the personnel management system, and the integration of big data technology into talent recruitment can comprehensively and accurately assess the ability of teachers [8]. And matched to the appropriate positions, so that the match between professional teachers and positions is more accurate [5]. Therefore, the use of big data technology for college talent recruitment not only improves the efficiency of recruitment and optimizes the recruitment process [15]. It also improves the quality of talent recruitment and provides reference for the intelligence of talent recruitment, which is of great practical significance [19].
In the context of the rapid development of big data, personnel recruitment has changed dramatically. This paper constructs a university personnel management system, mainly including three modules of personnel, faculty and labor, with different combinations of data elements composing different information, capable of integrating and analyzing various information. Data cleaning operation is carried out on the recruitment information collected in the personnel management system of colleges and universities, and the fuzzy C class mean algorithm is utilized to expand the clustering of user profiles to obtain the user profiles of different positions. The joint embedded neural network is used to match the user profiles and positions, set the relevant objective function values, and use the gradient descent to update and adjust the parameters of the objective function to minimize the value of the objective function, so that the recruiter can be matched to the position that meets their abilities. The application of big data technology improves the recruitment efficiency, optimizes the recruitment process, promotes the intelligent development of talent recruitment, and realizes more accurate talent selection and job matching in colleges and universities.
For schools, college staff recruitment is not only to attract more job seekers, but also to retain quality teachers who are suitable for the education sector. Literature [6] reviews the recruitment strategy of the education section in the UK and compares it with the healthcare service system, and concludes that the education section will place special emphasis on personal utility information in the recruitment process, which establishes the theoretical basis for this paper to optimize personnel recruitment in colleges and universities. Literature [11] designs quantitative methods such as multiple regression and factor analysis to identify the factors influencing employee performance from the realistic and ideal perspectives, respectively, so as to improve the retention rate of teachers in private schools. Employee performance plays a role in influencing personnel recruitment in colleges and universities, whether they are teaching or non-teaching staff, if the performance is at a desirable level, the easier it is to retain them. Literature [10] takes Australian higher education as a study aimed at optimizing the personnel recruitment process and strengthening educational talent. Quantitative interviews were conducted with nine universities to identify three themes: talent retention, talent development and talent attraction. Although this study provides new ideas for higher education recruitment programs, there are practical problems such as the difficulty of questionnaire collection and long data processing time. Literature [16] used Mplus software to analyze the collected data and discussed the mediating role between teachers’ well-being and turnover. The analysis showed that there is a positive and significant role between employee well-being and job satisfaction, which can provide data support for policy makers in university recruitment activities.
In the field of education, literature [9] states that the application of big data provides new opportunities for academia. Literature [1] proposes that intelligent recruitment stems from character recognition in social networks, using games or chatting with bots to match employees who are a good match for jobs. Incorporating several technologies and protocols to achieve intelligent recruitment, this research provides the underlying theory for the design of the relevant processes in this paper. Literature [14] constructs a global recruitment optimization mathematical model for the recruitment process in human resource management, considering multiple factors. The dataset contains the recruitment records of different populations in the past ten years, and a variable order Bayesian network is applied to improve the recruitment success rate. Literature [3] reviewed the relevant literature on human resources at this stage and concluded that personnel recruitment is very important for digital transformation. In order to better achieve efficient management of human resources, enterprises and institutions need to continuously adjust and optimize the recruitment process.
At this stage, there are quite a lot of researches about big data and personnel recruitment, but the research on applying big data technology to personnel management system of universities and colleges for intelligent recruitment is still insufficient. This paper combines the research ideas and theoretical basis of related scholars to explore the intelligent recruitment of big data technology in colleges and universities, aiming to improve the personnel management system of colleges and universities and guarantee the quality of education.
Personnel management system in colleges and universities usually includes three modules of personnel, faculty and labor, in which personnel is mainly for recruitment of talents, new faculty report and resignation transfer, etc., faculty management is mainly for information management and training and further training of faculty, etc., and labor management is for the management of faculty salary [12].
Appointment work in the personnel management system of colleges and universities mainly includes the appointment of cadres, professional and technical appointment and job setting, etc. Figure 1 shows the appointment process. The main users in the university personnel management system are system administrators, school-level leaders and personnel office managers, etc., in which the system administrator can manage the system, define user roles, set permissions and maintain basic personnel information. School-level leaders have the authority to view the information of the whole school, and can view the structure of the whole school’s faculty, and the personnel office managers can audit the information filled in by the faculty and staff, and maintain the basic information of the personnel [17].
Talent recruitment is the core function of the personnel management system of the university, mainly responsible for the recruitment of school talents, releasing the school’s recruitment information and notices, etc. The Personnel Office releases the notification of the recruitment plan, and the secondary unit collects and determines the needs of the recruitment position. After reviewing and analyzing the declared plans of the secondary units, the Personnel Office puts forward the proposal of the recruitment plan and reports it to the President’s Office for approval. After completing the approval to form the recruitment plan, external recruitment, candidates use the network to view the recruitment announcement, and register the relevant account, fill in the establishment. Personnel Office to view the resume, their qualifications, review passed, notify the candidates to participate in written tests and interviews. After the recruitment examination, the personnel system announces the employment list, arranges for the candidates to have a physical examination, and after passing the physical examination, handles the entry procedures, and the talent recruitment process ends.
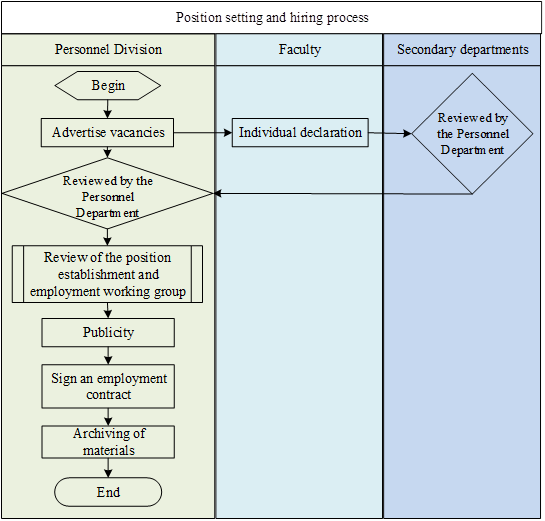
The creation and hiring of positions can be divided into two phases: one is to organize the positions in the school, and the other is to hire the faculty members to the positions. The Personnel Office publishes the vacant positions on the Internet, and the faculty and staff make declarations according to their own situations, and the secondary units make preliminary examinations of them and form preliminary opinions on employment. The Personnel Office evaluates the declarations of the secondary units and publicizes the results of the evaluation to complete the appointment of the faculty members.
After the appointment is completed, training and further training are usually provided to the faculty members in order to enhance their professional abilities. The Personnel Office will formulate relevant training and training programs and issue notices, and the faculty members will fill in the applications according to their needs, which will be reviewed by the departments and then summarized into the recommended training and training personnel for the approval of the leaders, who will ultimately obtain the qualification for training and training.
In order to be able to more comprehensively and accurately manage personnel information within universities, big data technology is usually used to manage personnel information [4]. Big data technology is mainly composed of different information with different combinations of data elements, which can integrate and analyze all kinds of information, including the basic information of faculty and staff and attendance records, etc., to facilitate the management of faculty and staff. At the same time, big data technology has the ability of data cleaning, which can identify and correct the errors of the data to ensure the integrity and accuracy of the data, which can complete many repetitive information management work, reduce the burden of the staff, reduce the error rate, ensure the security and privacy of the data to avoid the leakage of information, which has an important role and significance in the personnel management of the university [18].
According to the above steps, the analysis of the personnel management system of colleges and universities and the role of big data technology in the personnel management system of colleges and universities are completed. Before using big data technology to realize intelligent recruitment, it is necessary to extract the relevant recruitment information from the university management system and use data cleaning technology to clean the wrong data in the extracted recruitment information to supplement and correct the missing parts of the data [13]. After completing the cleaning of the data will be integrated into a whole, which will facilitate the processing and identification of the data.
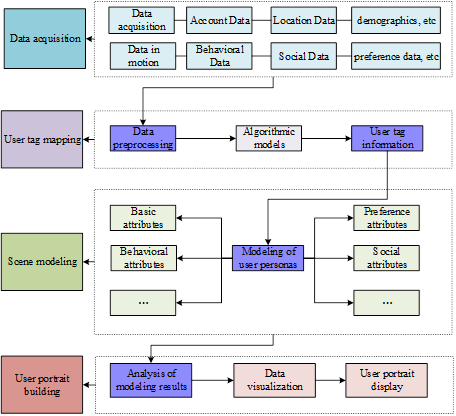
After extracting and processing the job information, the fuzzy C-mean algorithm is utilized to generate user profiles that match the jobs, and the user profile building process is shown in Figure 2. The fuzzy C-mean algorithm is mainly an algorithm to determine the clustering to which the data points belong with the degree of affiliation, which is an improvement of the traditional clustering algorithm.
Let the set of samples of job user profiles that meet the criteria be \(X=\left\{x_{1} ,x_{2} ,\ldots ,x_{n} \right\}\), where \(n\) represents the number of samples, which can be divided into \(c(2\le c\le n)\) clustering categories. Use \(\left\{A_{1} ,A_{2} ,\ldots ,A_{c} \right\}\) to represent the sample set and \(\left\{v_{1} ,v_{2} ,\ldots ,v_{c} \right\}\) to represent the center point of the class. The affiliation of \(x_{i}\) to category \(A_{k}\) in the sample set can be described by \(\mu _{ik}\). With \(U=\left(\mu _{ik} \right)_{n*c}\) representing the fuzzy classification matrix, the ultimate goal of the fuzzy C class mean algorithm is to find the best classification fuzzy matrix to reasonably cluster the user profiles that match the jobs so that the value of the classification function \(J_{b}\) is minimized. The definition of the objective function is shown below: \[\label{GrindEQ__1_} J_{b} (U,v)=\sum _{i=1}^{n}\sum _{k=1}^{c}\left(\mu _{ik} \right)^{b} \left(d_{ik} \right)^{2} ,\tag{1}\] \[\label{GrindEQ__2_} d_{ik} =d\left(x_{i} ,v_{k} \right)=\sqrt{\sum _{j=1}^{m}\left(x_{ij} -v_{kj} \right)^{2} } .\tag{2}\] where, \(b\in (1,\infty )\) represents the weighting parameter, \(d_{ik}\) represents the Euclidean distance, which is used to represent the distance between sample \(x_{i}\) and \(v_{{\rm k}}\) in category \(k\) clustering, and \(m\) represents the feature dimension of the sample.
The formula for the affiliation of sample \(x_{i}\) to category \(A_{k}\) in the fuzzy C-means algorithm is as follows: \[\label{GrindEQ__3_} \mu _{ik} =\frac{1}{\sum _{j=1}^{c}\frac{d_{ik} {}^{\frac{2}{b-1} } }{d_{jk} } } ({\rm i}\ne k) .\tag{3}\]
The affiliation in the fuzzy C-means algorithm has the property that the sum of the sample affiliations is 1. The equations for category \(A_{k}\) and center \(v_{{\rm k}}\) are as follows: \[\label{GrindEQ__4_} v_{k} =\frac{\sum _{i=1}^{n}\left(\mu _{ik} \right)^{b} x_{i} }{\sum _{i=1}^{n}\left(\mu _{ik} \right)^{b} } ,k=1,2,\ldots ,c .\tag{4}\]
After obtaining the distance between the category and the center, the appropriate clustering center is selected so as to obtain the optimal solution and complete the clustering of the post user profile.
A joint embedded convolutional neural network is used to match user profiles and jobs, and the job requirement information is used as a collection of job requirement items, the collection contains \(|S|\)-word requirement items, and matrix \(S\in R^{d\times |S|}\) can be built by using the word embedding method: \[\label{GrindEQ__5_} S=\left[w_{1} ,w_{2} ,\ldots ,w_{s} \right],w_{i} \in R^{d} .\tag{5}\]
The requirement item of the job as an input can be represented as follows: \[\label{GrindEQ__6_} j_{i} =\left[s_{1} ,s_{2} ,\ldots ,s_{n_{j_{i} } } \right]^{T},\tag{6}\] where \(n_{j_{i} }\) represents the number of requirement items of the job, which varies due to different jobs. Two one-dimensional convolutional layers are used as input layers, and the one-dimensional convolutional vectors with weight \(m\) and serialization \(S\) are dot-producted, and the output sequence \(C\) after dot-producting is: \[\label{GrindEQ__7_} c_{i} =m^{T} \cdot s_{i-|n|+1:i} .\tag{7}\]
In order to be able to reduce the training cost of the model, the BN algorithm is used to unfold the normalization of the features in the model and keep the size of the maximum pooling consistent with the inputs, and the demand information of the job is represented by the vector \(V_{n}^{j_{i} }\), and the job \(j_{i}\) can be converted into: \[\label{GrindEQ__8_} V_{n}^{j_{i} } =\left[V_{0}^{j_{i} } ,V_{1}^{j_{i} } ,\ldots ,V_{n_{j_{i} } }^{j_{i} } \right]^{T} .\tag{8}\]
To ensure consistency with the subsequent user profiling section, another maximum pooling operation is required, as follows: \[\label{GrindEQ__9_} V^{j_{i} } =\left[\max \left(V_{*,0}^{j_{i} } \right),\max \left(V_{*,1}^{j_{i} } \right),\ldots ,\max \left(V_{*,l}^{j_{t} } \right)\right]^{T} ,\tag{9}\] where \(V_{*,k}^{j_{i} }\) represents the vector dimension \(k\) and l represents the length of the requirement term.
When matching user portraits with jobs, the user portrait part needs to be convolved and maximally pooled, and the BN algorithm is used to reduce the training cost, and the student portraits are transformed into vectors \(V_{n}^{r_{i} }\) after processing, and the user portraits \(r_{i}\) can be converted into: \[\label{GrindEQ__10_} V_{n}^{r_{i} } =\left[V_{0}^{r_{i} } ,V_{1}^{r_{i} } ,\ldots ,V_{n_{r_{i} } }^{r_{i} } \right]^{T} .\tag{10}\]
An average pooling operation is launched for user profiles as follows: \[\label{GrindEQ__11_} V^{r_{i} } =\left[avg\left(V_{*,0}^{r_{i} } \right),avg\left(V_{*,1}^{r_{i} } \right),\ldots ,avg\left(V_{*,l}^{r_{i} } \right)\right]^{T} .\tag{11}\]
Launching a match between a user profile and a job requires minimizing the distance between the matched user and the job, as follows: \[\label{GrindEQ__12_} Loss(A)=\sum _{i=1}^{A}D \left(V^{r_{i} ,V^{j_{i} } } \right) ,\tag{12}\] where \(D\left(V^{r_{i} } ,V^{j_{i} } \right)\) represents the distance between the user portrait vector and the job vector.
The objective function for user portraits and posts is shown below: \[\label{GrindEQ__13_} J(\theta )=\min \left(\sum _{i=1}^{A}D \left(V^{r_{i} } ,V^{j_{i} } \right)-\sum _{f=1}^{F}D \left(V^{r_{f} } ,V^{j_{f} } \right)+\lambda \left\| \theta \right\| ^{2} \right) .\tag{13}\]
Usually, the smaller the objective function is, the stronger the model’s ability is, but if the model’s ability is pursued, the overfitting phenomenon will occur, and in order to prevent the model from this phenomenon, the objective function needs to be corrected. Add the regularization term or penalty term after the objective function, in which the regularization term belongs to the increasing function of the model complexity, \(\theta\) represents the weight vector, and \(\lambda \ge 0\) adjusts the coefficient of the regularization relation, and the objective function is corrected by using the L2 regularity term.
After completing the correction, in order to facilitate the confirmation of the degree of information matching between the user portrait and the job, the cosine similarity is utilized as the distance formula as follows: \[\begin{aligned} \label{GrindEQ__14_} D\left(V^{r_{i} } ,V^{j_{i} } \right)=&-\frac{V^{r_{i} } \cdot V^{j_{i} } }{\left\| V^{r_{i} } \right\| \times \left\| V^{j_{i} } \right\| } ,\notag\\ D\left(V^{r_{f} } ,V^{j_{f} } \right)=&-\frac{V^{r_{f} } \cdot V^{j_{f} } }{\left\| V^{r} f\right\| \times \left\| V^{j_{f} } \right\| } . \end{aligned}\tag{14}\]
The parameter \(\theta\) of the objective function is solved to minimize the value of the objective function and complete the matching of jobs and user profiles. The gradient descent method is utilized to update parameter \(\theta\), and the specific formula is as follows: \[\label{GrindEQ__15_} \theta =\theta -\eta \times \nabla (\theta ) ,\tag{15}\] where \(\eta\) represents the rate of learning, that is, the size of parameter update, and \(\nabla (\theta )\) represents the gradient of the objective function \(J(\theta )\).
By solving the update of the objective function parameters, the appropriate objective function value is obtained to complete the matching of user profiles and jobs [7].
The experimental environment for intelligent recruitment under big data is set up to collect the recruitment information released by the personnel management system of universities using big data technology. The test environment is shown in Table 1, setting up reasonable experimental equipment and software, adjusting the parameters of the software to ensure the accuracy of the test results.
| Lab Equipment | Model number |
|---|---|
| Server | Dell PowerEdge R740xd |
| CPU | Intel Xeon Gold 6248R |
| Memory | SATA HDDs |
| Data Processing | Hadoop |
| Machine Learning Algorithms | TrnsorFlow |
| Routers | Cisco ISR 4000 Series |
| Firewalls | Check Point 15600 |
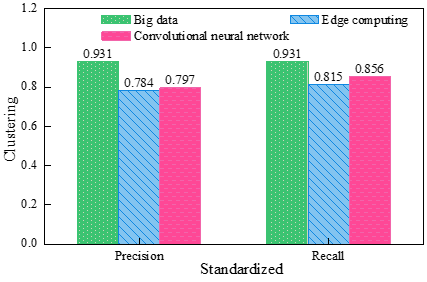
In order to better prove the clustering accuracy and clustering recall of big data technology for interviewer profiling, a randomly selected dataset of interviewers from a university is used as a test dataset, and the clustering effect of different methods is shown in Figure 3. The clustering accuracy and recall of the three techniques are significantly different, but the big data technology is better than the other two algorithms, with an average accuracy and recall of 0.931. The difference between the clustering results of edge computing and convolutional neural network is smaller, between 0.784-0.856, and the clustering effect of big data technology is more accurate, not only analyzing user preferences and behavioral characteristics, but also making user clustering become faster and improve the performance of personnel management system in colleges and universities.
Job Match Accuracy is mainly used to measure the degree of match between the job and the candidate, and to assess whether the candidate sought by Big Data is suitable for the needs of the job. If the matching rate of the job is high, it means that the candidate searched by big data is suitable for the job and can meet the needs of the job. The job matching rate is shown in Table 2, and it can be concluded that the job matching rate using big data technology is high, and it is able to match the job that meets the needs based on the user profile, and it is able to match the job that agrees with the recruitment that requires mastery of office software when the user profile is mastery of office software, and the matching rate is 98.1%. When the educational background is a bachelor’s degree, it can also be matched to jobs that recruit bachelor’s degree, with a high degree of matching. So big data technology can choose the right job according to the candidate’s own characteristics and realize the accurate matching of jobs. It reduces the time cost of the traditional recruitment process, and can more efficiently and accurately match the right talent and promote the intelligent development of talent recruitment.
| User Profile | Candidate Characteristics | Job Requirements | Match rate |
|---|---|---|---|
| Educational Background | Master’s degree, major in computer science | Master’s Degree in Computer Science | 95% |
| Work Experience | 3 years working experience | At least 2 years of work experience is required | 97.2% |
| Professional Skills | Proficient in office software | Proficient in office software | 98.1% |
| Personality Characteristics | Team player | Good communication skills, team spirit and proficiency in software are required. | 94.3% |
| Language skills | Fluent in English reading and writing | Good communication skills in English | 97.5% |
| Professional Skills | Master the writing of Java language | Be able to write Java language programs | 96.7% |
| Work Experience | 5 years of work experience | At least 1 year working experience is required | 97.1% |
| Educational Background | Bachelor’s degree | Bachelor degree or above required | 92.3% |
Recruitment efficiency test is mainly used to measure the recruitment efficiency of big data technology, whether it can quickly recruit suitable talents, whether it can arrange interviews as soon as possible, etc., so as to assess the reasonableness of big data technology recruitment.
Recruitment cycle, interview arrangement, resume screening ratio, etc. are used as recruitment efficiency indicators, and Table 3 shows the results of the recruitment efficiency test. Using big data technology for recruitment, it takes only 25 days from the posting of the job to the onboarding of the candidate, which is faster than traditional recruitment in terms of recruitment efficiency. And the completion rate of recruitment is higher, which reduces the pressure of personnel personnel, and the interview arrangement is more rapid, from determining the interview to arranging the interview, it only takes 3 hours, and the recruitment efficiency is 91.2%, which reduces the waiting time of the candidates and improves the efficiency of the candidates to look for a job. And big data technology can conduct preliminary screening of resumes, reducing the burden on staff, reducing the cost of recruitment, improving the cost-effectiveness of talent recruitment, and the personnel management system of colleges and universities can achieve the best performance.
| Recruitment Efficiency Indicators | Metrics | Data | Recruitment efficiency |
|---|---|---|---|
| Recruitment cycle | Number of days from job posting to candidate onboarding | 25 days | 90% |
| Interview Arrangement | Time from when a candidate is confirmed for an interview to when the interview is scheduled | 3 hours | 91.2% |
| Recruitment Completion Rate | Percentage of employees found by Sing Sing in a given cycle | 76% of the time | 89% |
| Candidate Feedback | Time to provide feedback on candidate questions | 2 hours | 92.3% |
| Resume Screening Ratio | Percentage of effective resumes screened using big data technology | 84% of the total number of hours | 90.2% |
Candidate satisfaction test is mainly used to measure the candidate’s satisfaction with the interview arrangements and interviewer, if the candidate’s feedback results are better, the use of big data technology to match the position in line with the candidate’s expectations, and the interviewing company’s attitude is more positive, the candidate experience is better. Candidate satisfaction test results as shown in Table 4, candidates are more satisfied with the job matching of big data technology, more satisfied with the completeness of the job information release, at about 7.9 points, in the interviewer’s professionalism is more in line with the needs of the interviewer, 8.1 points, and more satisfied with the interview results of the feedback is higher, 8.2 points. So the positions matched by big data technology are closer to the candidates’ expectations, and the candidates are more satisfied with the processes of recruitment information, interview process and feedback of interview results. It proves that big data technology can optimize the recruitment process, make the recruitment process easier and faster than the traditional form of recruitment, avoid the candidates to have a long waiting time, and improve the efficiency of recruitment.
| Assessment Indicators | Indicator Description | Satisfaction Rating |
|---|---|---|
| Recruitment process efficiency | Recruitment process is clear and efficient | 8.5 out of 10 |
| Accuracy of recruitment information | Recruitment information is accurate and complete | 7.9 points |
| Interviewer’s professionalism | Interviewers are polite and professional | 8.1 points |
| Relevance of interview questions | Whether the interview questions are related to the specialty | 8.2 points |
| Interview arrangement | Whether the interview arrangement is reasonable | 7.8 points |
| Feedback on interview results | Whether the feedback of the interview result is timely | 8.2 points |
Response time test is mainly to measure the feedback time of big data technology in matching candidates and assessing and predicting talent potential, in general, the shorter the response time, it means that the big data technology is faster in processing the data, and it can feedback the matching results in time, for the candidate module and the talent potential prediction module, Table 5 shows the response time test. The shortest response time is 0.5s and the maximum response time is 3.2s when the big data technology matches the candidates, and the shortest response time is 1s and the maximum response time is 3.3s when the talent potential is predicted, which indicates that the response time of big data technology is faster, can quickly complete the matching of talent and the prediction of talent potential, and timely feedback of the corresponding results, reducing the waiting time and improving the talent recruitment process. Waiting time, improve the efficiency of talent recruitment, reduce the cost of talent recruitment, and improve the user experience.
| Modules | Average response time | Maximum response time |
|---|---|---|
| Candidate matching | 0.5s | 1s |
| Candidate matching | 2.1s | 3.2s |
| Candidate matching | 2s | 3s |
| Candidate matching | 1.1s | 2.1s |
| Talent potential prediction | 1s | 3s |
| Talent potential prediction | 2s | 2.3s |
| Talent potential prediction | 2.1s | 3.3s |
The privacy protection of data is mainly about the protection measures and strategies for candidates’ private information to prevent the leakage of candidates’ information, which can be collected and utilized by unlawful elements and affect the candidates’ daily life. If the privacy protection rate of big data technology is high, it means that the big data technology provides protection to the candidates and maintains the interests of the candidates, and the intelligent recruitment process is guaranteed.
Table 6 shows the results of privacy protection comparison, in the protection of 20 candidates’ information, the protection rate of big data technology is at 99.2%, and the number of leaks is 1. Artificial intelligence technology and blockchain technology have 4 and 6 more leaks respectively compared to big data technology, and blockchain technology has the lowest protection rate of 89%. This can show that big data technology has better privacy protection, up to 100%, which can protect candidates’ personality information and prevent personal information from being tampered and collected. Big data technology provides a safe recruitment environment for candidates, improves their experience and satisfaction, safeguards personal interests while protecting social stability, and promotes the development of intelligent talent recruitment.
| Number of candidate information | Big Data Technology | Artificial Intelligene | Blockchain technologies | |||
|---|---|---|---|---|---|---|
| Number of Leaks | Protection Rate | Number of Leaks | Protection Rate | Number of Leaks | Protection Rate | |
| 20 | 1 | 99.2% | 5 | 92.1% | 7 | 89% |
| 30 | 0 | 100% | 6 | 91% | 10 | 87% |
| 15 | 0 | 100% | 5 | 92.1% | 8 | 88% |
| 27 | 1 | 99.2% | 7 | 90.5% | 10 | 86.9% |
| 35 | 1 | 99% | 6 | 91% | 7 | 89% |
| 32 | 0 | 100% | 6 | 91% | 10 | 86.5% |
Big data has been given a lot of attention in the field of technical human resources recruitment, and has been used in the accurate prediction of human resources supply and demand for intelligent assistance in specific recruitment, personalized targeted analysis of recruitment candidates, and so on, and has achieved certain results. It can be seen that big data has brought many favorable impacts to university human resources recruitment work, such as optimizing recruitment channels, reducing recruitment costs, and enhancing the degree of matching between people and jobs. However, it should also be noted that because human resource managers have not yet fully adapted to and mastered big data, there are many hidden concerns in applying it to the recruitment process, such as the lack of data utilization ability, data utilization cost, and data security issues. Therefore, it is necessary to pay full attention to the problems brought by big data in the process of using big data for human resources recruitment, and take effective measures to avoid and solve potential problems. Optimize the effect of the use of big data in recruitment to achieve progress in enterprise management.
At present, there is still a lot of room for improvement in the study of countermeasures for problems caused by the application of big data in enterprise human resources recruitment, and future research can propose more effective and targeted countermeasures for the problems caused by the application of big data in the field of recruitment in order to improve the research in this field.
This paper is based on the recruitment process of personnel management system in colleges and universities to clarify the application direction of big data technology. The fuzzy C class mean algorithm is utilized to unfold clustering on the user portrait, and the user portrait is obtained. The joint embedded neural network is used to match the user portrait and the position, formulate the value of the objective function, minimize the value of the objective function, and complete the matching of the position. Application and exploration found that the matching of positions is more accurate, the highest matching is 98.1%, and the shortest response time is 0.5s and the maximum response time is 3.2s when the big data technology is matching candidates. Candidates’ satisfaction on the feedback of interview results is relatively high, which is 8.2 points. This shows that the talent recruitment of big data technology can efficiently match the right position, improve the efficiency of recruitment, and the matched position meets the needs of the user, which improves the satisfaction of the candidate, reduces the waiting time of the candidate, promotes the development of talent recruitment, and attracts more excellent talents for the university.
Ning Zhou was born in Shaoxing Zhejiang China, in 1984. He obtained a master’s degree from East China Normal University in China. He is currently employed at Zhejiang Agriculture and Forestry University and holds a temporary position at Xinjiang Institute of Technology. His main research direction is higher education management and human resources.
Yiming Wu was born in Jinhua Zhejiang China, in 1986. He obtained a doctoral degree from Muwon University in South Korea. He is currently employed at Zhejiang Agriculture and Forestry University. His main research direction is higher education management and public policy.