
The IMO Member State audit is a review of a member’s competence of implementation of IMO instruments , aiming to identify behaviors that do not meet the requirements of the instruments and to take timely corrective measures for improvement of implementation of IMO instruments [1]. The evaluation of implementation of IMO instruments involves assessing the consistency and effective compliance between implementation behavior and instruments requirements. Traditional manual examination, relying on extensive experience, has limitations in terms of evaluation effectiveness and efficiency. Additionally, the diverse instruments requirements increase the difficulty of evaluation [2]. The development of intelligent techniques provides opportunities for enhancing evaluation methods. Prototype networks and meta-learning are particularly applicable to this research topic [3]. Meta-learning (M-L) addresses tasks using a learning algorithm and improves the algorithm based on more learning experiences. Compared to traditional deep learning algorithms, M-L better addresses shortcomings such as insufficient data samples and low computational efficiency, offering improved generalization ability [4, 5]. M-L is characterized by intelligence, generation and evolution. Chen J et al. developed a machine learning model based on M-L forbearing fault detection, achieving higher accuracy [6]. Li R et al. proposed a machine translation model integrat ing M-L training strategies for domain adaptation, demonstrating effective results [7]. Gao K et al. introduced M-L to improve the classification of spectral images, particularly in scenarios with small sample sets [8]. Chen L et al. analyzed M-L’s over-parameterization in limited supervised data learning, proposing a two-layer structure to address the issue of overfitting [9]. Xu Z’s team introduced a general M-L method to adapt to new tasks, simplifying the inequality between various tasks [10].
Prototype networks create a prototype representation for each classification and determine the query to be classified by calculating the distance between the classification prototype vector and the query point. Xu W et al. applied prototype networks to image representation for global and local feature learning [11]. Du F et al. improved prototype networks for aerospace structural health detection, enhancing model practicability [12]. Liang Y et al. integrated prototype networks into a convolutional neural network for brain disease diagnosis, achieving superior classification performance [13]. Ji Z et al. proposed an improved prototype network to explore class distribution information, showing superior performance [14]. Chen W’s team built a recognition model combining CNN and prototype network, enhancing precision and demonstrating good generalization ability [15].
In summary, M-L and prototype networks are favored by scholars in various research fields. However, few researchers have applied these methods to evaluate the implementation of IMO instruments. This study innovatively introduces intelligent methods, such as prototype networks and M-L, into the evaluation model, aiming to ensure consistency and effectiveness in evaluation of implementation of IMO instruments. This study constructs an M-L model based on Prototypical Networks to evaluate the consistency and effective compliance of audits.
The IMO member state audit has experienced two stages from a voluntary audit mechanism to a mandatory audit mechanism. Figure 1 shows the implementation of the promulgation during the phase of the voluntary audit mechanism.
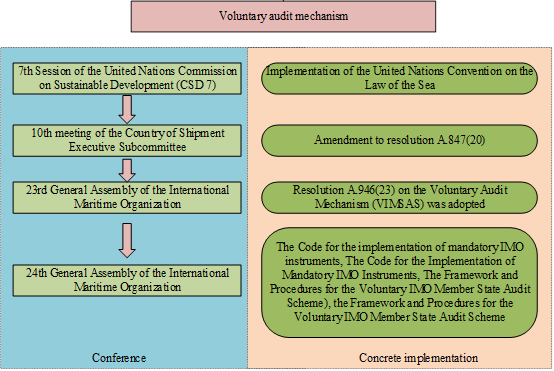
During the voluntary audit mechanism phase, at the 10th meeting of the Implementation Sub-Committee on Flag State, a number of States submitted proposals for amendments to resolution A.847(20) to facilitate Flag States better implement the IMO instruments. The proposal received broad support. Simultaneously, it was considered necessary to focus not only on flag states but on the responsibilities of all member States. Subsequently, an agreement was reached that a rule was needed to cover the responsibilities of member States in terms of flag, coastal, and port states.
In November 2003, as indicated in resolution A.946(23), the IMO Assembly adopted a decision to continue the voluntary audit mechanism, requesting the IMO Council to develop procedures and other modalities to ensure that the voluntary audit mechanism is treated as a highly focused matter. The III code are designed to guide Member States in fully fulfilling their duties and responsibilities regarding Flag State, Coastal State, and Port State. They aim to formulate and establish the standards of the audit that can be referred to by all Member States. In the development of the framework and procedures, specific requirements, principles, scope, responsibilities, procedures, and other forms for the implementation of the voluntary audit mechanism have been clarified.
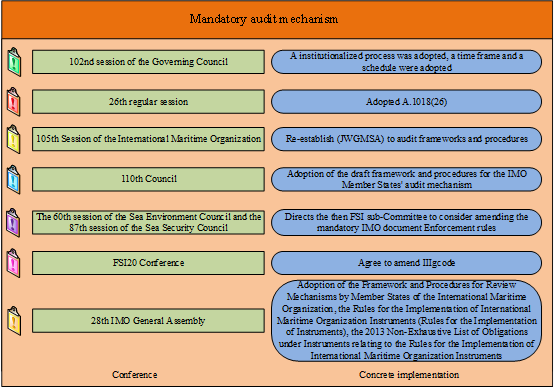
Figure 2 illustrates the implementation of the mandatory audit mechanism phase. At this stage, in July 2009, during the 102nd session of the Council, institutionalization was achieved, and a timeframe and schedule were adopted in principle. In November 2009, resolution A.1018(26) endorsed the Council’s decision to undertake a phased process to promote the audit mechanism. The resolution of Council A.1018(26) decided to re-establish JWGMSA to review the framework and procedures. The JWGMSA completed an audit of the framework and procedures at its 6th meeting.
In 2013, the 28th IMO Assembly adopted the relevant content of the mandatory audit and issued three documents on the mandatory audit, guiding member states to implement instruments in accordance with the relevant provisions. In addition, IMO updates the list in a timely manner according to the revision of the system of instruments.
To advance this strategy, the Quality Management System is the basis and guidance for the implementation of audits. In consideration of the establishment of the audit scheme, IMO has developed the formulation of procedures, records, principles, etc. Its certification aims to strengthen member countries’ confidence in the IMO member state audit scheme by indicating compliance with the internationally recognized management standard and to provide a solid foundation for the further enhancement of audits.
The audit scheme is currently implemented as a mandatory audit scheme, representing one of the essential means by which the IMO ensures that flag states, port states, and coastal states fulfill their responsibilities. The mandatory audit scheme operates on a seven-year cycle, with the first round commencing in 2016 and scheduled to conclude in 2022. Twenty-five countries are expected to undergo audit each year. The scope of the mandatory audit for the implementation of the Convention includes the internalization of the conventions, supervision, inspection, certification, RO management, maritime investigation and so on.
After each mandatory audit, the audit team issues a detailed audit report. The report explicitly outlines the identified problems for member states to refer during the correction process.
IMO publishes the audit report in accordance with paragraph 7.4.3 of the IMO Audit Procedures for Member States. Periodically, IMO releases the consolidated audit summary report, sorting out and summarizing the mandatory audit reports issued during the period and listing the existing problems. Subsequently, the root causes are analyzed, and corresponding corrective measures are proposed to assist member states in better identifying the problem. This, in turn, facilitates member states effectively achieve the objectives described in paragraphs 5.2.1, 5.2.3, and 5.2.4 of the IMO Member States Audit Framework. The objective of the audit is to promote capacity-building and provide relevant technical assistance.
It aims to determine the extent to which technical assistance can facilitate related states in the fulfillment of their responsibilities. The results and lessons learned from the audit are shared among all member states while maintaining the privacy of specific states by anonymizing their names. The audit systematically provides feedback on all lessons learned to create an appropriate basis for considering the suitability and feasibility of the Organization’s legislation.
The issues identified are represented in the form of findings and observations in the consolidated audit summary report. Findings refer to situations that do not comply with the mandatory provisions of IMO instruments or the requirements of audit standards, while observations pertain to situations that do not conform to the non-mandatory requirements stipulated in the IMO instruments.
The core of the mandatory audit lies in comparing the current implementation practices of IMO state members with the requirements of IMO instruments. The objective is to identify practices that do not meet the instruments requirements, allowing for the implementation of appropriate corrective measures to enhance implementation capacity. One of the most crucial steps in this process is assessing the consistency and effective compliance of existing implementation practices with the instruments requirements.
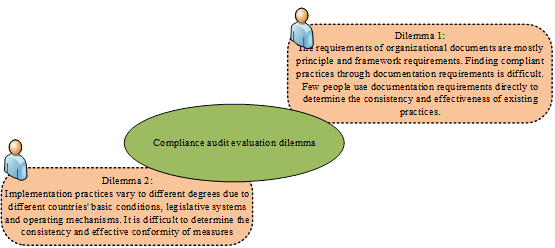
IMO instruments requirements are primarily in principle and in the nature of framework requirements. Determining the consistency and effectiveness of current practices directly from the instruments requirements is challenging, requiring expertise from an IMO-accredited auditor who has undergone systematic training and extensive practice. Therefore, there are varying degrees of differences in the basic conditions, legislative systems, and operating mechanisms of each member state. The measures taken for the same instruments may differ, making it difficult to judge the consistency and effective compliance of these measures. To address this practical dilemma, this paper proposes a swift and straightforward method for consistency and effective compliance assessment.
This paper adopts the Meta-Learning (M-L) method for research.
The current mandatory audit, which has been put into practice since 2016, is short of relevant data, especially authoritative data recognized by IMO, which fall into the category of small samples that can be dealt with Meta-Learning[16]. Existing Machine Learning Models (MLM) have limitations in applicability for studies of small samples, as they often require substantial data support for training, which small samples cannot provide.
To address the issue of limited data and enhance computing efficiency, this paper employs the M-L strategy, which effectively resolves the data and computation bottleneck, presenting an improved deep learning algorithm, a popular direction in small-sample deep learning.
This paper utilizes a prototype network for small samples, as introduced by Jake Snell, Kevin Swersky, Richard S. Zemel in “Prototypical Networks for Few-shot Learning,” as the basic model.
The prototype network is an M-L method based on metric learning. Its core principle involves learning class prototypes for rapid learning and generalization [17]. A class prototype is an abstract representation of samples within a class, akin to the aggregation or central point of all samples of that class in the characteristic space. The prototype network classifies by comparing the input sample with each class prototype.
In each task, the prototype network first computes prototypes based on the support set, forming the mean value of the characteristic vector of samples of the same category in the support set [18]. Subsequently, using the Query Set composed of samples requiring classification, the prototype network calculates the distance measure (such as Euclidean distance) between the input sample and the prototype of each class [19]. Finally, it obtains the similarity of the input sample and the prototype of each class to complete the classification.
The support set comprises a small number of labeled samples, while the query set contains unlabeled samples consistent with the sample space of the support set but distinct from it. When computing an embedding center,\(S_{k}\) represents a support set of class \(f_{\theta}(x_{i})\) represents the embedding function, and \(x_{i}\) denotes the input value.
\[c_{k} = \frac{1}{|S_{k}|} \sum_{i} f_{\theta}(x_{i}).\]
The distance of the new sample to the embedding center of each class is calculated as \(d_{i} = d(f_{\theta}(x), c_{i}), i = 1,2,…,N\). These distances are then mapped using the Softmax function to obtain the probability \(\widehat{y_{i}} = \text{softmax}(d_{1}, d_{2},…,d_{k})\) for each category.
The training target optimizes the cross-entropy loss function through SGD. \(y\) is the true value, and \(\widehat{y}\) is the predicted value, yielding \(L(y,\widehat{y}) = -\sum_{i=1}^{N'}y_{i} \log \widehat{y_{i}}\).
Assuming the current dataset is \(D\), we can represent the samples inside it as \(\{(x_{1}, y_{1}), (x_{2}, y_{2}), …, (x_{n}, y_{n})\}\). Here, \(x\) denotes the vector, and \(y\) represents a classification label.
For each classification, \(n\) sample points are randomly generated for it from the total sample set. The generated final support set is denoted as \(S\) for each class. Similarly, a query set \(Q\) is generated by randomly selecting \(n\) sample points for each classification from the total sample set.
For the sample points inside the support set, the encoding formula \(f_{\varphi}\) is used to produce a prototype representation for each category. The encoding formula \(f_{\varphi}\) can be any method of information extraction.
For each category, generate its prototype representation as:
\[\text{i.e., ClassPrototype}(c) = \frac{1}{S} \sum_{(x_{i}, y_{i}) \in S} f_{\varphi}(x_{i}).\]
For the query set, the encoding of the query set is also generated, and the distance between the prototype representation of the query set and the support set is calculated. The probability that the sample belongs to each category is calculated as follows:
\[\text{i.e., } p_{\varphi}(y=k|x) = \frac{\exp(-d(f_{\varphi}(x), c))}{\sum_{k}\exp(-d(f_{\varphi}(x), c))}.\]
The loss function is calculated as:
\[J(\varphi) = -\log p_{\varphi}(y=k|x).\]
In this study, a prototype network is employed for predictions on the dataset. The BERT pre-training model was used for coding and as a feature extractor, encoding each sample as a 64- dimensional vector (embedding) and embedding it in the prototype network framework. In a prototype network, samples of each class are mapped to a prototype vector, which can be computed by calculating the mean or center of all samples under the same category. For each class, a prototype vector is computed, and for an unseen sample, the distance between it and the prototype vector of each class is calculated.
In this study, a support set and query set were designed. The support set is equivalent to the training set in each small task, containing N classification labels, with each label having K samples. The query set is equivalent to a test set in each small task, containing Q unclassified samples.
Accuracy rate (ACC) was utilized to evaluate the predictive performance in this paper. The ACC reflects the proportion of correctly predicted samples for each category relative to the overall samples. The calculation method is as follows:
\[\text{ACC} = \frac{\text{Number of Correctly Predicted Samples}}{\text{Total Number of Samples}}\]
To better evaluate accuracy, a Confusion Matrix is introduced. In image accuracy evaluation, the Confusion Matrix compares the classification results with the actual measured values, displaying the accuracy of the classification results. The Confusion Matrix is operated by comparing the position and classification of each observed pixel with the corresponding position and classification in the classified image. The Confusion Matrix is mainly applied to observe the performance of various categories.
In accordance with IMO member state audit , the issues identified in the mandatory audit are categorized into two types: findings and observations. Findings refer to situations where the practices related to performance violate mandatory provisions, while observations refer to situations where the practices violate non-mandatory provisions. Findings are a crucial indicator directly related to the performance of IMO members. Therefore, corrective measures for findings are the research object in this study.
The study collected 961 findings from the consolidated audit summary report. The corrective actions of findings are considered as the analysis subtext, and the associated clause requirements are taken as the classification standard, resulting in a total of 40 categories. This means that 961 pieces of data need to be classified into 40 categories.
Firstly, in the data processing stage, the experiment carried out data cleaning. The model reads the data and restores the abbreviations present in the text fields, especially the abbreviations of proper nouns, with the help of regular expressions. Simultaneously, the English stopword dictionary is employed in data processing to remove stop words and further clean the data.
Secondly, considering that BERT and other pre-trained models require uniform input length, text data needs to be treated during the pre-processing stage. This operation is performed to determine the maximum length of the text in the training set and set a reasonable threshold to truncate and fill the text.
To test the performance of the prototype network on small sample classification and an unknown class, two strategies were developed to verify the optimization effect of the prototype network-based M-L algorithm using heuristic selection:
Select all text data, with a total of 40 categories, and divide the training stage set and test stage set in a 5:5 ratio.
Select all text data, which comprises 40 categories. Select 20 categories as the training stage set, while the remaining 20 categories are chosen as the test stage set.
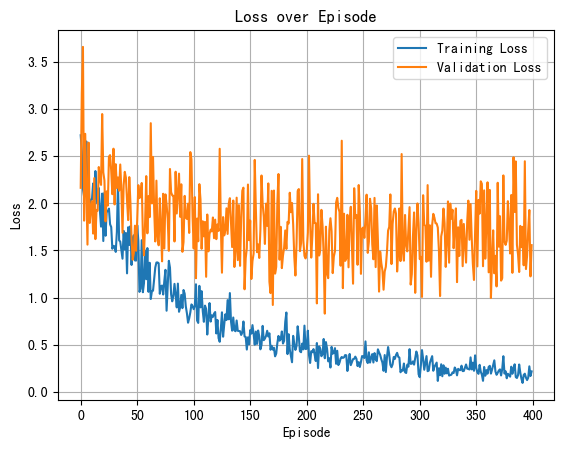
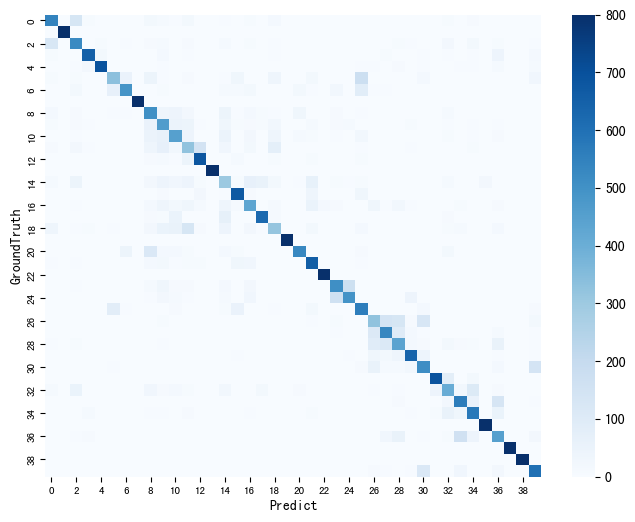
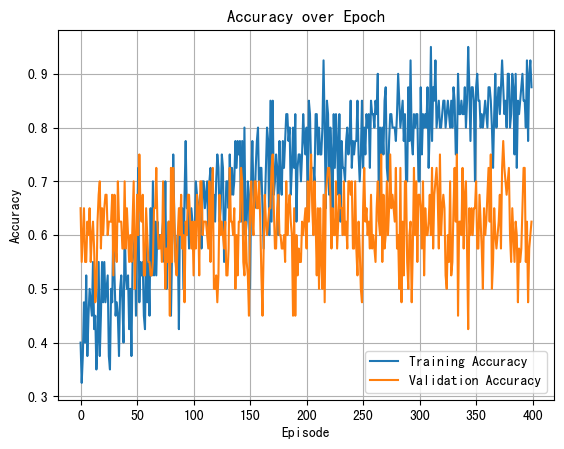
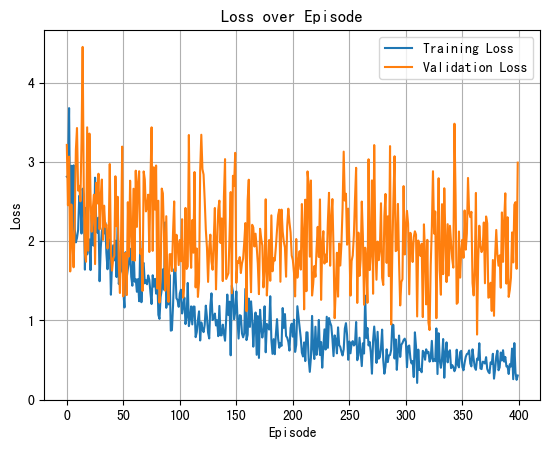
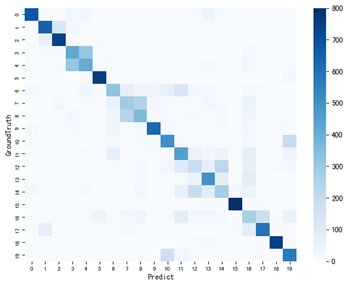
The accuracy value of strategy 1 is 71.61%, and that of strategy 2 is 65.78%. In summary, in terms of overall classification accuracy, strategy 1 and strategy 2 both reach a high level, although there is a slight difference in prediction accuracy.
Using M-L, a method based on the prototype network is developed for assessing the consistency and effectiveness between current practices and instruments requirements. Two simulation strategies and methods are proposed to test the optimization effect of the model on heuristic selection. The research results indicate that the constructed model achieves a relatively good classification level for both experimental strategies and has strong generalization ability, demonstrating its effectiveness in enhancing the evaluation of implementation of IMO instruments. Compared with traditional manual evaluation, the accuracy values of the proposed method under the two strategies are 71.61% and 65.78%, respectively, reflecting increased intelligence. Additionally, the proposed model enhances the applicability of principled and framed IMO instruments requirements in guiding implementation practices, guiding different member states to improve evaluation efficiency, and better implementing relevant instruments requirements.
The authors declare no conflicts of interest regarding this work.
The authors confirm their contributions to the paper as follows: study conception and design: Min Zhu; data collection: Min Zhu; analysis and interpretation of results: Min Zhu; draft manuscript preparation: Linchi Qu. All authors reviewed the results and approved the final version of the manuscript.