
Corpus linguistics is an emerging discipline, which can be used to discover problems and phenomena in language, provide rich materials and evidence for language research, verify the results of researchers’ introspective rational thinking, and enrich research results [1]. This paper is a corpus-based study of the semantic function of Chinese “negation + X” modals, using a corpus linguistic approach to study the semantic function of Chinese “negation + X” modals [2,3]. A modal is a subjective attitude expressed by a speaker about the truth value of a proposition or the reality state of an event, and is strongly subjective in nature. Mood conveys the speaker’s attitude and opinion and is an important part of carrying the meaning of a sentence [4]. The “negative + X” modals are the most frequently used modals in modern Chinese, mainly including “fortunately”, “fortunately”, “fortunately” and “fortunately”. In recent years, there have been more and more studies on “negation + X” modals, but most of them rely on descriptions or structural differences, and few of them are based on the actual corpus, combining the common and the ephemeral levels. The study of the “negation + X” modals has seldom been conducted from the actual corpus, combining the coprime and the epochal levels. The study of semantic function was first proposed by Ma Qingzhu and is mainly derived from semantic-functional grammar [5,6]. It is based on semantics and emphasizes the coordination of “semantics, structure and expression”, which is an important guidance for the ontology of Chinese grammar and the study of teaching Chinese as a foreign language.
With the popularization of computers and the rapid development of the Internet, modern society has fully entered the information era [7]. Human activities in the Internet will produce a large amount of information, and text as the main information carrier, most of the information in the Internet is presented in the form of text. In the face of the massive amount of text data, the use of manual methods to organize, analyze and obtain effective information on text data has the problem of low efficiency and cannot meet the actual needs [8]. As an electronic calculator for high-speed computing, computer is an excellent tool for processing massive text data and can realize high-speed processing of text data. However, due to the complexity and ambiguity of text data, it is difficult for computers to understand text contents that are easily understood by humans. In order to enable computers to understand text content and process it accordingly, humans have started to study various theories and methods for computers to effectively understand human natural language, both natural language processing techniques [9]. Natural language processing integrates linguistics, computer science and mathematics, and is mainly used for text-related tasks such as machine translation, text classification, text clustering, and opinion monitoring. The semantic function of the “negation morpheme + X” class of modals is a fundamental part of the research. In the process of vectorized representation, the vector used to characterize the text contains the contextual semantic information of the text, and finally the semantic difference between the text is expressed by calculating the distance between the semantic features of the text [10,11]. The semantic differences between the texts are finally expressed by calculating the distance between the semantic features of the texts to quantify the similarity between the texts. The results of the study on the semantic function of “negation + X” modal words are useful for automatic question and answer systems, information retrieval, automatic text summarization, the semantic function of “negation + X” modal words in modern Chinese, and public opinion monitoring. For example, in automatic question and answer systems, the similarity analysis is performed between user questions and questions in the question database, and the answer corresponding to the question with the highest similarity in the database is used as the response [12]. The user’s input is analyzed to find the web pages with high similarity to the user’s input and push them to the user. In modern Chinese “negation + X” class modal word semantic function, the calculation result of “negation + X” class modal word semantic function is used to complete the task of text classification and clustering, “negation + X” class modal word semantic function The calculation accuracy of the “negation + X” class affects the results of the “negation + X” class in modern Chinese [13].
On the one hand, we want to provide empirical evidence for the typological study of “negation + X” modals with a real and reliable large-scale corpus; on the other hand, we want to investigate “negation + X” modals in depth, enrich case studies, and deepen the understanding of “negation + X” modals in the academic community; finally, through case studies of “negation + X” modals, we want to provide reference and help for dictionary compilation and Chinese teaching [14].
In summary, the study of the semantic function of the “negation + X” class of modals in modern Chinese based on a corpus of communication technology and big data shows that the semantic function of the “negation + X” class of modals, as a fundamental research element in natural language processing, is important for other tasks. The study shows that the semantic function of the “Negation + X” class is important for other tasks. At the same time, in public security work, the “negation + X” type of modal word semantic function also has great potential to support the completion of public opinion control work, especially the implementation of public opinion discovery and other related work. At the same time, the existing technology can support the implementation of the semantic function of “negation + X”, which proves the feasibility of implementing the semantic function of “negation + X”.
In the field of linguistics, semantic analysis is defined as a process of “computing the relationships between different grammatical structures”. The “grammatical structures” here can be words, phrases, sentences, paragraphs or whole texts, depending on the granularity. So, how to calculate the relationship between these grammatical structures [15]. Generally speaking, a sentence, paragraph or article can be considered as a collection of basic words and phrases, and the relationship between these structures can be calculated by the similarity of the elements they contain. The reason why the bag-of-words model cannot analyze the semantics of words with “negation + X” type of modal words is that it cannot decompose words into more abstract elements. The semantic analysis is then carried out on a larger granularity of grammatical structures, such as sentences, paragraphs, etc. The “concept” here refers to the basic semantic elements extracted from the linguistic knowledge, as shown in Figure 1.

Then, semantic analysis of “negation + X” modal words refers to calculating the correlation between words and concepts, and representing words as a vector in the concept space; semantic analysis of text refers to representing text as a computer-recognizable data structure based on word vectors. In particular, if text is considered as a weighted sum of word vectors, then semantic analysis can be seen as a mapping from a vector space with words as dimensions to a vector space with concepts as dimensions, as in Eq. 1:
\[\label{e1} \mathop d\limits^ \to = Q \times {\mathop d\limits^ \to _c}. \tag{1}\]
In the natural language processing task, each word can be regarded as a key-value pair and query is the information related to the task. The calculation process is expressed in Eq. 2 as follows.
\[\label{e2} {\text{ Attention }}({\text{ Source }},{\text{ Query }}) = \sum\limits_i {{\text{ Similarity }}} \left( {{\text{ Key}}{{\text{ }}_i},{\text{ Query }}} \right)*{\text{ Value}}{{\text{ }}_i}. \tag{2}\]
Since the calculated similarity does not have a fixed interval, it is necessary to normalize the similarity to obtain the weight of each value and select the softmax function to complete the weight calculation. The specific calculation process is shown in Eq. 3 .
\[\label{e3} {a_i} = {\text{ Soft}}{{\text{ }}^{\max }}\left( {{\text{ Similarity}}{{\text{ }}_i}} \right) = \frac{{{e^{{\text{Similarit}}{{\text{ }}_i}}}}}{{\sum\limits_i {{e^{{\text{Similarity}}{{\text{ }}_i}}}} }}. \tag{3}\]
After all the concepts are derived, the concept space can be constructed. According to the mapping relationship between concepts and class labels, the class label concept matrix S can be initialized, where each row represents the final weight calculated in the second stage multiplied by the corresponding value and summed up to obtain the final weight value, see Eq. 4.
\[\label{e4} {\text{ Attention }}({\text{ Source, Query }}) = \sum\limits_i {{a_i}} \cdot {\text{ Value}}{{\text{ }}_i}. \tag{4}\]
A concept, each column represents a class label. If concept \({C_k}\) is derived from class label \({L_n}\), then \({S_{kh}} = 1\), otherwise \({S_{kh}} = 0\). If direct derivation or split derivation is used, the matrix S can be generated automatically; if combinatorial derivation is used, some values of S need to be defined manually. Since the concept and class labels are not too large in magnitude, this part of labor consumption is acceptable. However, the concept derivation only defines the dimension of the space, and an important next task is if the correlation between words or texts and each dimension is calculated, as shown in Figure 2 and Table 1.
| Monolayer corpus | Multilayer Corpus | |
| Single label corpus | Direct derivationDirect | Derivation |
| Multi label corpus | Combined derivation | Combination |
Doc2Vec is an unsupervised algorithm that generates sentence, paragraph and document vector representations without a fixed training text length. It not only solves the problem of word order and word sense in text, but also solves the problem of sparsity and high dimensionality after text vectorization. Based on the Word2Vec structure, Doc2Vec also contains two training models, so this paper uses the PV-DM model to generate feature vectors for Web service description text, as shown in Figure 3.
The PV-DM model is shown in Figure 4, for a given sentence such as “Didn’t you just say it looks good? Take a look”, each sentence is transformed into a corresponding sentence vector and is used as a column of the segment matrix D. At the same time, each word is transformed into a column of the segment matrix D. Meanwhile, each word is transformed into a word vector with the same dimension as the sentence vector and is used as a column of the word matrix W. In the training phase, words of fixed length are slidingly extracted from the sentences for data sampling each time, and any one word in the sampling window is selected as the predicted word, and the rest are used as the input words. During the training of each sentence, the ParagraphID is kept constant, thus ensuring that the semantics of the whole sentence is adopted for each training.
In the above example, the word “must” expresses a strong sense of necessity, and cannot be replaced by “must”, if it is replaced by “must”, it becomes a sentence in which “he If it is replaced by “have to”, it becomes the “he” or “you” in the sentence to make or want to make the behavior action, the expressed becomes the dynamic state [16]. The first two examples are both strong imperatives based on objective facts, and the last two are both strong imperatives based on the speaker’s request. In the example, “he has a big test tomorrow” is an objective fact and a necessary factor for the subject of the sentence, “he”, to study intensively tonight, “must” here expresses the subject of the sentence must do so The “must” here expresses the strong sense of necessity for which the subject of the sentence must “drive the night”. The “must” of the example expresses the strong necessity that the hearer must keep applying windex to cover up the disgusting “smell of books” based on the objective situation that he cannot stand it. The “must” in the example is based on the speaker’s (Mencius’) demand, and expresses the strong necessity that “to achieve more than normal performance” you must endure unbearable pain. The same is true for the “must” example, which expresses the compulsion of the listener. The behavioral action of “drawing by others” has a strong necessity, as shown in Table 2.
| Modal meaning/Modal | Necessity conjecture | Will meaning/Strong will | Will meaning/Weak will | Necessary meaning/Strong necessity | Necessary meaning/Weak necessity | Counterproductive sense/Anti personal expectation | Counterproductive sense/Antisocial expectation |
| Must | + | – | + | + | + | + | – |
| Have to | + | + | – | – | + | + | + |
In addition, this paper continuously updates the model parameters by random gradient descent training. When the error converges, the training is finished and the sentence vector corresponding to each sentence in the whole sample set can be obtained. Based on the above steps, this paper converts the Web service description text into Doc2Vec feature vectors, which can be directly clustered with Web service.
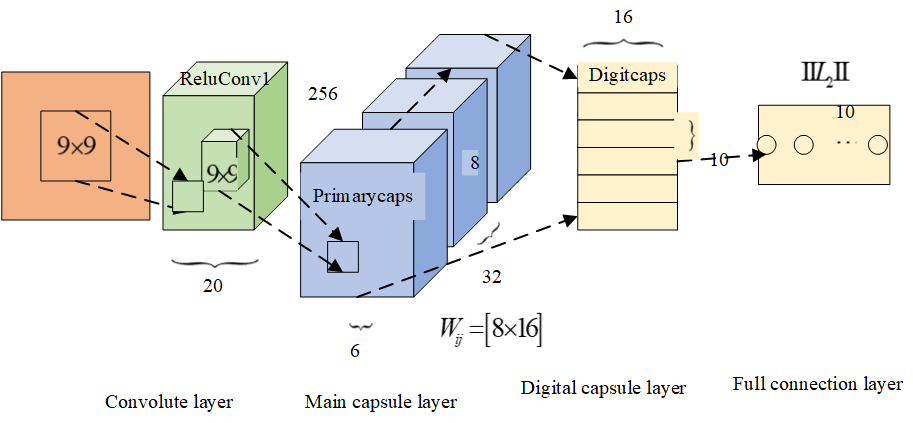
The modern Chinese “negation morpheme + X” class modal word semantic database model combines capsule network and text in different dimensions by using the advantages of each, which can extract semantic features of text more accurately. The model improves the traditional attention mechanism according to the characteristics of similarity tasks, and proposes the mutual attention mechanism to make it more suitable for handling similarity tasks. Caps Net-Bi GRU Modern Chinese “Negation + X” class modal word semantic database model is shown in Figure 5.
This method uses the mutual relationship between two texts to be analyzed to analyze the important words in the text and assign a higher weight to them, which changes the traditional attention mechanism that only uses the information in a single text to complete the weight assignment. Compared with the attention mechanism, the mutual attention mechanism is more suitable for handling the task of similarity analysis. Secondly, the capsule network is improved by combining the dynamic routing mechanism with the attention mechanism, and the words that are not related to the semantics of the text are regarded as noisy capsules and given smaller weights in the process of dynamic routing mechanism, so that it can better extract the semantic features of the text, as shown in Table 3.
| Sentence position/Modal | Sentence prefix/Quantity | Sentence prefix/Proportion | In sentence/Quantity | In sentence/Proportion | Ellipsis/Quantity | Ellipsis/Proportion | Private use/Quantity | Private use/Proportion |
| Must | 103 | 33.2% | 204 | 65.8% | 2 | 0.7% | 1 | 0.3% |
| Have to | 98 | 31.6% | 208 | 67.1% | 4 | 1.3% | 0 | 0 |
The twin neural network structure is used in extracting the semantic features, i.e., the exact same network structure is used to process the two word vector matrices, as shown in Figure 6.
As can be seen from Figure 7, the dynamic routing algorithm is described in detail below and is improved for the specificity of the natural language domain.
In summary, the distribution of the sentences of the modal words “must” and “must not” was obtained by randomly selecting 200 sentences from each corpus, as shown in Table 4.
| Modal | Must/Declarative sentence | Must/Imperative sentence | Must/Exclamatory sentence | Must/Question | Have to/Declarative sentence | Have to/Imperative sentence | Have to/Exclamatory sentence | Have to/Question |
| Quantity | 100 | 18 | 26 | 56 | 129 | 12 | 22 | 37 |
| Proportion | 50% | 9% | 13% | 28% | 64.5% | 6% | 11% | 18.5% |
In the above table, the modals “must” and “must” are often found in declarative sentences to express people’s affirmative attitude, and less often in imperative sentences. Although the proportion of both in exclamatory and interrogative sentences is lower than that in declarative sentences, they are more effective in expressing people’s emotion and tone in exclamatory and interrogative sentences. Both of them can be found in positive and negative questions, specific questions and cross-examinations, but not in optional questions and right and wrong questions: if the sentence is questioned with doubt, it enhances the questioning tone of the sentence, if the sentence is asked without doubt, it has the effect of a rhetorical question, and in rhetorical questions led by words such as “can’t/doesn’t”, it serves to further enhance the rhetorical tone of the sentence, express dissatisfaction or discontent. In the rhetorical question led by the words “can’t/can’t”, it has the effect of further enhancing the tone of the rhetorical question and expressing dissatisfaction or helplessness.
In addition, it is important to note that recurrent neural networks can lead to “negation + X” gradient disappearance and gradient explosion due to the concatenation of weight matrices, which results in some weight parameters having too much or too little influence on the loss function. Also, RNN has the problem of long distance dependence. When calculating the output of a time step, the hidden state near the time step has a greater impact on the output, and the hidden state far from the time step has a smaller impact on the output, resulting in the loss of information. When the text length is too long, when processing the last words, the network will forget the information of the words that are close to the front, both the traditional RNN does not have the ability to learn at a distance, therefore, the model can be considered to be optimized as Figure 8.
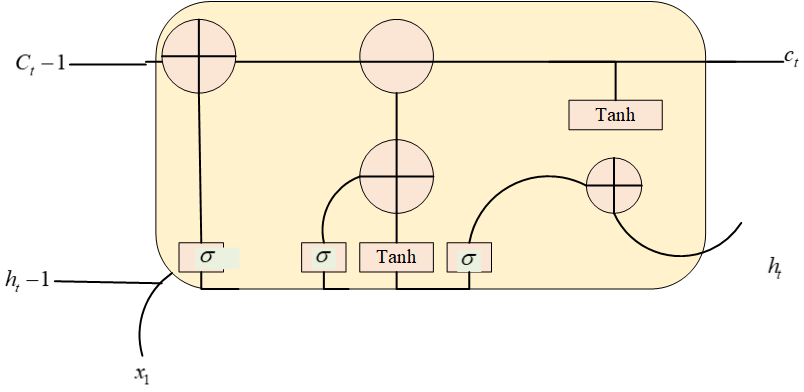
In the LSTM network structure diagram, tC is the cell state of the network node, and th is the output of the network node, where the cell state is the core of the LSTM network, which continuously changes the cell state by removing or adding information through the gating mechanism, and in this way the information is transmitted in the LSTM network.
After the above two networks, the model will get two semantic feature matrices of the text, both transform the text into two semantic feature matrices, and analyze the semantic similarity between the two texts is to analyze the similarity between the semantic feature matrices corresponding to the two texts. Because the two semantic feature matrices are extracted by different networks, the distribution of the modal words “not to” and “not to” was obtained, as shown in Table 5.
| Modal/Style | Must/Quantity | Must/Proportion | Have to/Quantity | Have to/Proportion |
| Novel | 189 | 54% | 150 | 42.8% |
| Telefilm | 37 | 10.6% | 62 | 17.7% |
| Wiitty dialogue | 27 | 7.7% | 29 | 8.2% |
| Dialogue | 9 | 2.6% | 20 | 5.7% |
| Newspapers and periodicals | 53 | 15% | 35 | 10% |
| Practical writing | 30 | 8.6% | 43 | 12.2% |
| Historical biography | 5 | 1.4% | 11 | 3.1% |
From the above table, we can see that the modal words “must” and “must” are widely distributed in the language, and can be found in spoken language such as novels, TV and movies, comic dialogues, and written language such as newspapers, application texts and historical biographies.
In fact, this shows that the modal word “non-get” appeared before “non-want”, but the two words were formed at about the same time. They are a combination of the affirmative modal adverb “not” and the modal verbs “to get” and “to be”, respectively, in the construction “not X not Y “As they are used more frequently, the “not Y” may or may not appear in the sentence, prompting them to develop into modals that express the subjectivity of the speaker. In terms of semantic function, both can express cognitive, moral and motivational moods, which are specifically expressed as: (a) the inevitable speculative sense of inferring the inevitability of things; (b) the necessary sense of believing that things or behaviors are necessary to appear or occur; (c) the will sense of expressing the subjective will of the speaker; and (d) the counter-expected sense of not matching expectations.
The differences in the expressions of necessary meaning, willing meaning and anti-expectation meaning are obvious: (a) when expressing necessary meaning, “not to” does not express strong necessary meaning; (b) when expressing willing meaning, “not to” does not express strong willing meaning and “not to” does not express weak willing meaning; (c) when expressing anti-expectation meaning, “not to” can express both anti-individual and anti-social expectation meaning, while “not to” only expresses anti-social expectation meaning, based on this, we can see the example training loss gradient curve in Figure 9.
The confusion matrix is shown in Table 6.
| Positive | Negative | |
| 1 | TP | FN |
| 0 | FP | TN |
In the dichotomous problem, the label values are divided into positive and negative classes. In the task of “Negative + X” type of modal function, as shown in Table 7.
| Parameter name | Parameter value |
| Epoch | 25 |
| Batchsize | 512 |
| Dropout | 0.3 |
| Capsule dimension | 64 |
| Dynamic route iterations | 3 |
| BIRU neurons | 100 |
The loss function uses binary cross-entropy because the model is ultimately a binary problem, and the use of binary cross-entropy is more suitable for handling binary problems, as shown in Figure 10.
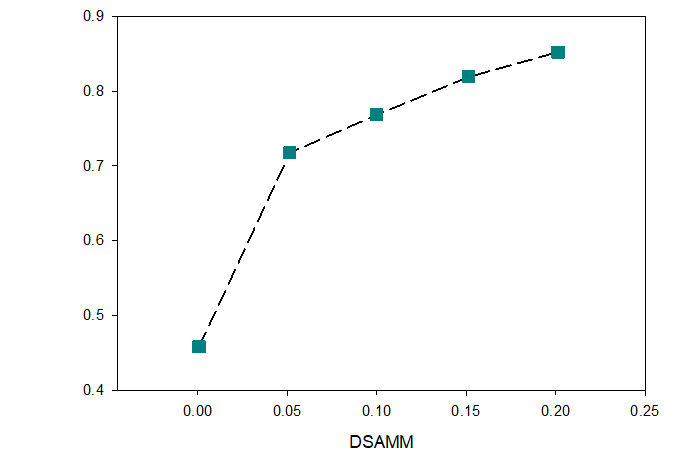
As shown in the corresponding graphs, Jaccard similarity coefficients stand out in the semantic address matching task using string similarity-based methods, with higher prediction metric values than the other two string similarity-based methods when both classifiers, SVM and RF, have been determined. The final performance of the three presents a situation of Jaccard > Jaro > Levenshtein. When controlling for the metrics of the string similarity methods, a comparison of the classifier performance shows that the classifier using RF as the task consistently outperforms SVM, as does the other two groups using machine learning methods, indicating that the random forest classifier method achieves better prediction accuracy. Among all the string matching-based methods, the Jaccard+RF method performs the best with a precision, recall and F1 value of 0.91, which is the best result among all the previous methods in this experiment on this task. Thus, the final validation model can be obtained as Table 8.
| Address matching method | Result index item/Accuracy | Result index item/Recall | Result index item/F1 value |
| Levenshtein distance+support vector machine classifier | 0.849 | 0.795 | 0.822 |
| Levenshtein distance+random forest classifier | 0.875 | 0.819 | 0.885 |
| Jacard similarity coefficient+support vector machine classifier | 0.890 | 0.881 | 0.912 |
| Jacard similarity coefficient+random forest classifier | 0.914 | 0.911 | 0.864 |
| Jaro similarity+support vector machine classifier | 0.902 | 0.807 | 0.854 |
| Jaro similarity+random forest classifier | 0.891 | 0.858 | 0.874 |
| Word2Vec+support vector machine classifier | 0.832 | 0.762 | 0.797 |
| Word2Vec+random forest classifier | 0.910 | 0.879 | 0.895 |
| Conditional random field+word2vecd+support vector machine classifier | 0.826 | 0.751 | 0.788 |
| Conditional random field+word2vec+random forest classifier | 0.895 | 0.846 | 0.871 |
| Word2Vec ESM | 0.969 | 0.961 | 0.965 |
| DSAMM | 0.987 | 0.982 | 0.984 |
The study of the semantic function of modern Chinese “negation + X” modals based on communication technology and big data corpus is a fundamental research element of natural language processing, and is a current hot research topic. Based on previous research results, this study defines and classifies modern Chinese “negation + X” modals, and combines the CCL corpus and BCC corpus (including microblogs, blogs, novels, movies, comedies, application texts, newspapers, etc.) with real and valid corpora. We use a variety of theories and methods to analyze the meaning and form of speculative modals “not necessarily”, “but”, and “may”. The process of lexicalization and grammaticalization of four groups of modal words with similar semantics, including “no” and “but”, “have to” and “have to”, and “might as well” and “might”, and the differences in semantic functions of these four groups of modal words are compared and analyzed. The semantic function of the “negation + X” modal words has both training samples and no training samples, and there are different techniques to complete the analysis of the semantic function of the “negation + X” modal words. In this paper, we propose two improved models to improve the performance and computational efficiency of the model, which are based on two technical routes: supervised learning and semi-supervised learning. The experimental results show that the models are effective in improving the computational efficiency of the WMD distance algorithm, and the proposed model improves in all evaluation indexes compared with other models. In practical use, different methods can be chosen for different scenarios to accomplish the relevant tasks.
The author declares no conflicts of interest regarding this work.