
The aim of this article is to fill a gap in the literature by presenting a general framework which allows to produce explicit formulas for the number of nodes in a Smolyak grid.
Let \(U_i\) be a quadrature rule on \([-1,1]\), i.e. \(U_i : C^0([-1,1])\to\mathbb R\) or an interpolation rule i.e. \(U_i: C^0([-1,1])\to C^0([-1,1])\) which evaluates an unknown function \(g:[-1,1]\to\mathbb R\) on a finite set \(S_i\subset [-1,1]\). The Smolyak rule turns a sequence of univariate quadrature or interpolation rules \(U_1,U_2,\ldots\) into a quadrature or interpolation rule on \([-1,1]^d\). Here, \(|S_i|\leqslant |S_{i+1}|\) for all \(i\in \mathbb N_{\geqslant 1}\) and the Smolyak rule in \(d\) dimensions of level \(\mu\in\mathbb N\) is defined as \[\label{smolyak-rough} Q^d_\mu = \sum\limits_{d\leqslant |\mathbf i|\leqslant d+\mu}\bigotimes_{k=1}^d \Delta_{i_k},\tag{1}\] where \(\Delta_{i}=U_{i}-U_{i-1}\) as long as \(i>2\) and \(\Delta_1 = U_1\), \(\mathbf i\in \mathbb N^d_{\geqslant 1}\) is a multi-index with positive entries and \(|\mathbf i|:=i_1+\ldots + i_d\) denotes its \(1\)-norm (see [10]). [5] shows that (1) includes a lot of cancellation and can be expressed as (see also [11], Lemma 1).
\[Q^d_\mu = \sum\limits_{\max\{d,\mu+1\}\leqslant |\mathbf i|\leqslant d+\mu}(-1)^{d+\mu-|\mathbf i|}\binom{d-1}{d+\mu-|\mathbf i|}\bigotimes_{k=1}^d U_{i_k}.\]
This last expression implies in which nodes an unknown function \(u:[-1,1]^d\to\mathbb R\) needs to be evaluated, if \(Q^d_{\mu}(u)\) is computed: We attach to the sequence \(U_1,U_2,\ldots\) of univariate quadrature or interpolation rules the sequence \(\mathcal S = S_1, S_2, \ldots\) of sets \(S_i\subset[-1,1]\) of evaluation nodes such that \(f(i) = |S_i|\) is a non-decreasing function \(f:\mathbb N_{\geqslant 1}\to \mathbb N_{\geqslant 1}\), called growth function of \(\mathcal S\). The Smolyak grid in \(d\) dimensions with level \(\mu\) is then given by \[\Gamma_d(\mu) = \bigcup_{\max\{d,\mu+1\}\leqslant |\mathbf{i}|\leqslant d+\mu}\times_{k=1}^d S_{i_k}.\]
If the sequence \(\mathcal S\) is nested, i.e. if \(S_k\subset S_{k+1}\) for all \(k\in \mathbb N_{\geqslant 1}\), then \[\Gamma_d(\mu) = \bigcup_{|\mathbf{i}|= d+\mu}\times_{k=1}^d S_{i_k}.\]
Since the Smolyak rule has been introduced to overcome the curse of dimensionality, there is great interest in determining its computational cost i.e. to count the number of nodes in such a grid for a given sequence \(\mathcal S\), a given dimension \(d\) and a level \(\mu\). This number will be denoted by \(\mathrm N_d(\mu)\), where the growth function \(f\) of the sequence \(\mathcal S\) will be clear from the context. For our purposes, we consider isotropic grids but we remark that our counting argument at no point needs spatial isotropy but only that the sets used in each dimension share the same growth function.
For practical implementation, it might be of interest to count the number of nodes needed during the generating process of such grids, before duplicates are deleted, i.e. there might be interest in finding a simpler formula for \[\mathcal N^{\Sigma}_d(\mu)=\sum\limits_{\max\{d,\mu+1\}\leqslant |\mathbf{i}|\leqslant d+\mu}\prod_{k=1}^df(i_k),\] which doesn’t require to compute all the multi-indices \(\mathbf i\in \mathbb N_{\geqslant 1}^d\) such that \(\max\{d,\mu+1\}\leqslant |\mathbf{i}|\leqslant d+\mu\). The number \(\mathcal N^{\Sigma}_d(\mu)\) is of course independent of the nestedness or non-nestedness of the sequence \(\mathcal S\), however, if the sequence is nested, counting points in the Smolyak grid with duplicates boils down to finding a formula for \[\mathcal N_d(\mu)=\sum\limits_{|\mathbf{i}|= d+\mu}\prod_{k=1}^df(i_k).\]
We will provide formulas for the quantities \(\mathrm N_d(\mu)\) for the case of \(\mathcal S\) being nested and \(\mathcal N_d(\mu)\) for general \(\mathcal S\) only as \[\mathcal N^{\Sigma}_d(\mu) =\!\!\!\!\! \sum\limits_{k=\max\{0,\mu+1-d\}}^\mu\!\!\!\!\! \mathcal N_d(k).\]
For some specific growth functions, there are explicit formulas for \(\mathrm N_d(\mu)\) available in the literature, see for instance [5,9, 2]. Also, a lot is known about upper bounds for \(\mathrm N_d(\mu)\) or asymptotic formulas [9,5, 12,7, 11,8]. The contribution of [3] provides tables with values for \(\mathrm N_d(\mu)\) and code which allows to generate them. Also, in [4], tables with values are provided.
Our approach allows to find closed formulas for the quantities \(\mathrm N_d(\mu)\) and \(\mathcal N_d(\mu)\) by using generating functions and dimension-wise induction, thus generalizing previous formulas obtained by of [8,7, 2] and [9]. To this end, we define \[G_d(x) = \sum\limits_{\mu=0}^\infty\mathrm N_d(\mu)x^\mu \text{ and }\mathcal G_d(x) = \sum\limits_{\mu=0}^\infty\mathcal N_d(\mu)x^\mu.\]
We are now ready to state our main result which will be restated for the convenience of the reader in Propositions 2.1 and 2.2:
Theorem 1.1. It holds that \(G_d(x) = G_1(x)^d(1-x)^{d-1} \text{ and }\mathcal G_d(x) = \mathcal G_1(x)^d,\) where \[G_1(x) = \mathcal G_1(x) = \sum\limits_{\ell=0}^\infty f(\ell+1)x^\ell.\]
We will include explicit formulas for some specific growth functions \(f\) related to usual sequences \(\mathcal S\) which are used in practice. Such sequences are for example based on:
1. Equidistant nodes without boundary: \[\mathring{\mathrm{E}}(n) = \left.\left\{\frac{2k}{n+1}-1\right| k\in\{1,\ldots,n\}\right\} , n\in \mathbb N_{\geqslant 1}.\]
For these points, the sequence given by \(S_k = \mathring{\mathrm E}(f(k))\) is nested if \(f(k) = m^k-1\) for \(m\in\mathbb N_{\geqslant 2}\).
2. Equidistant nodes with boundary and Chebyshev nodes of the second kind: \[\mathrm{E}(n) = \left.\left\{\frac{2(k-1)}{n-1}-1\right| k\in\{1,\ldots,n\}\right\}, n\in\mathbb N_{\geqslant 2},\] \[\mathrm{C}_2(n) = \left.\left\{\cos\left(\frac{k-1}{n-1}\pi\right)\right| k\in\{1,\ldots,n\}\right\}, n\in\mathbb N_{\geqslant 2}.\]
The sequences \(S_k = \mathrm{E}(f(k))\) and \(S_k = \mathrm{C}_2(f(k))\) respectively become nested if \(f(k)=m^k+1\), \(m\in\mathbb N_{\geqslant 2}\). Sometimes it is convenient to define \(\mathrm E(1) = \mathrm C_{2}(1) = \{0\}\).
3. Chebyshev nodes of the first kind:
\[\mathrm{C}_1(n) = \left.\left\{\cos\left(\frac{2k-1}{2n}\pi\right)\right| k\in\{1,\ldots,n\}\right\}, n\in\mathbb N_{\geqslant 1}.\]
Here, the sequence \(S_k = \mathrm{C}_1(f(k))\) is nested if \(f(k) = 3^k\) or \(f(k)=3^{k-1}\).
4. Leja nodes (see [6]): Any sequence \((x_n)_{n\in\mathbb N_{\geqslant 1}}\) such that \(x_1\in [-1,1]\) and \[x_n \in\mathop{\mathrm{arg\,max}}\limits_{x\in [-1,1]} \prod_{j=1}^{n-1}|x-x_j|, n>1,\] is called a Leja-sequence. For such a sequence, we let \[\operatorname{L}(n) = \left\{x_k|k\in\{1,\ldots,n\}\right\}.\]
Note that \(S_k = \mathrm{L}(f(k))\) is nested for every choice of a non-decreasing growth function \(f\), in particular, for \(f(k)=k\). There is a symmetrized version of Leja nodes available which become nested for the growth function \(f(k) = 2k-1\) (see [1]).
Example 1.2. Consider a Smolyak grid based on the sequence \(\mathcal S\), where \(S_k = \mathrm C_1(3^k)\). As we show below, according to (3), one obtains \[\begin{aligned} \mathrm N_2(\mu) & = 3^{\mu+1}(2\mu+3),\\ \mathrm N_3(\mu) & = 3^{\mu+1}(2\mu^2+10\mu+9), \end{aligned}\] so that the cardinalities in Figure 1 can be computed.
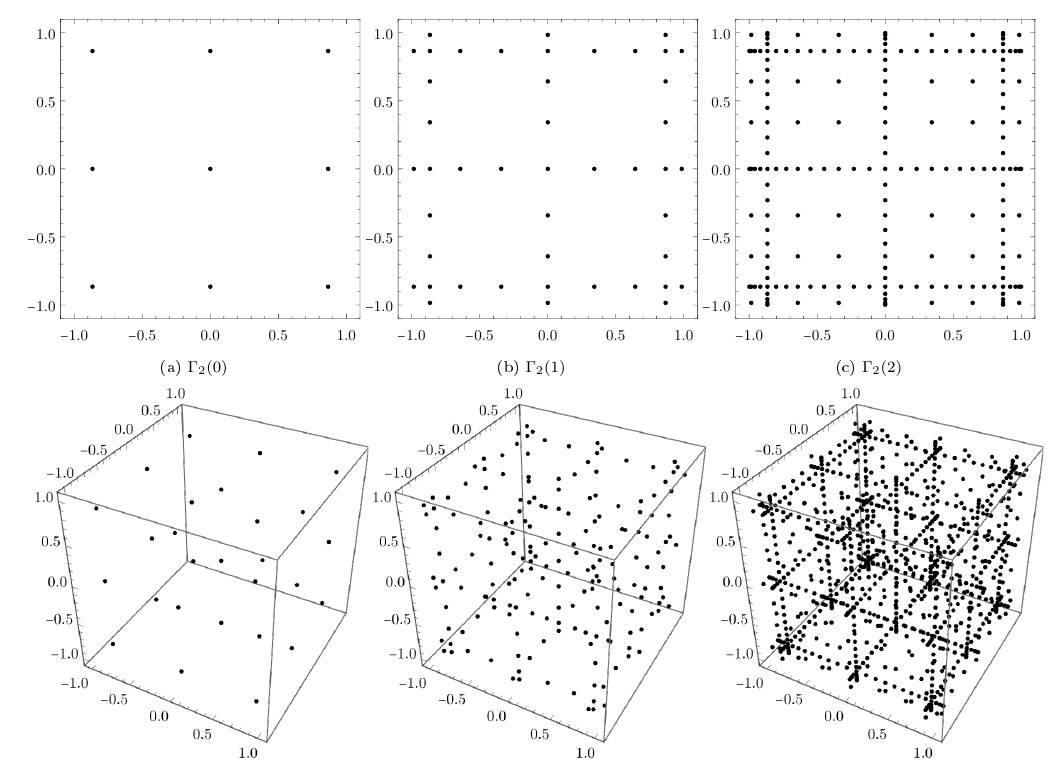
We first consider a nested sequence \(\mathcal S\) with growth function \(f(k)=|S_k|\). Then we have the following proposition:
Proposition 2.1. The generating function \[G_d(x) = \sum\limits_{\mu=0}^\infty \mathrm N_d(\mu)x^\mu,\] satisfies \(G_d(x) = G_1(x)^d(1-x)^{d-1},\) where \(\displaystyle G_1(x) = \sum\limits_{\ell=0}^\infty f(\ell+1)x^\ell.\)
Proof. We have \[\begin{aligned} \Gamma_{d+1}(\mu) & = \bigcup_{|\mathbf i| = d+1+\mu}\times_{k=1}^{d+1} S_{i_k} = \bigcup_{\ell = 0}^{\mu} \Gamma_d(\mu-\ell) \times S_{\ell+1},\\ & = \Gamma_d(\mu)\times S_{1}\cup \bigcup_{\ell = 1}^{\mu} \Gamma_d(\mu-\ell) \times S_{\ell+1},\\ & =\Gamma_d(\mu)\times S_{1}\cup \bigcup_{\ell = 1}^{\mu} \Gamma_d(\mu-\ell) \times \left(S_{\ell+1}\setminus S_{\ell}\right), \end{aligned}\] where the key point is that the last line writes \(\Gamma_{d+1}(\mu)\) as a disjoint union because of the nestedness of \(\mathcal S\). This idea already appears in [7,8,9]. It follows that \[\label{recursion} \mathrm N_{d+1}(\mu) = f(1) \cdot \mathrm N_d(\mu) + \sum\limits_{\ell=1}^\mu (f(\ell+1)-f(\ell))\mathrm N_d(\mu-\ell),\tag{2}\] from which we deduce using the Cauchy product, since \(\mathrm N_d(k)=0\) provided \(k<0\), \[\begin{aligned} G_{d+1}(x) & = f(1) \cdot G_d(x) +\sum\limits_{\mu=1}^\infty \left(\sum\limits_{\ell=0}^{\mu-1}(f(\ell+2)-f(\ell+1)) \mathrm N_d(\mu-1-\ell)\right)x^\mu,\\ & = f(1)\cdot G_d(x) + x \sum\limits_{\mu=0}^\infty\left(\sum\limits_{\ell=0}^{\mu}(f(\ell+2)-f(\ell+1)) \mathrm N_d(\mu-\ell)\right)x^{\mu},\\ & = f(1)\cdot G_d(x) + x \left(\sum\limits_{\ell=0}^\infty(f(\ell+2)-f(\ell+1))x^\ell\right)\left(\sum\limits_{\mu=0}^\infty \mathrm N_d(\mu)x^\mu\right). \end{aligned}\]
Since \[\sum\limits_{\ell=0}^\infty(f(\ell+2)-f(\ell+1))x^\ell = G_1(x)-f(1)-x\, G_1(x),\] we conclude that \[\begin{aligned} G_{d+1}(x) & = f(1)\cdot G_d(x) + \left(G_1(x)-f(1)-x \,G_1(x)\right)G_d(x), \\ & = G_d(x)G_1(x)(1-x), \end{aligned}\] from which the claim follows by induction on \(d\). ◻
Let now \(\mathcal S\) be a (not necessarily nested) sequence with growth function \(f\) and consider the generating function \[\mathcal G_d(x) = \sum\limits_{\mu=0}^\infty \mathcal N_d(\mu)x^\mu.\]
Proposition 2.2. It holds that \(\mathcal G_d(x)= \mathcal G_1(x)^d\), where \(\displaystyle \mathcal G_1(x) = \sum\limits_{\mu = 0}^\infty f(\mu+1)x^\mu\).
Proof. We start by observing that \[\begin{aligned} \mathcal N_{d+1}(\mu)& = \sum\limits_{|\mathbf i|=d+1+\mu}\prod_{k=1}^{d+1}f(i_k) = \sum\limits_{|\mathbf i|=d+1+\mu}\left(\prod_{k=1}^{d}f(i_k)\right) f(i_{d+1}),\\ & = \sum\limits_{\ell=1}^{\mu+1}f(\ell)\mathcal N_d(\mu+1-\ell), \end{aligned}\] so that using the Cauchy product \[\begin{aligned} \mathcal G_{d+1}(x) & = \sum\limits_{\mu=0}^\infty \sum\limits_{\ell=0}^{\mu}f(\ell+1)\mathcal N_d(\mu-\ell)x^\mu =\left(\sum\limits_{\ell=0}^{\infty}f(\ell+1)x^{\ell}\right)\left(\sum\limits_{\mu=0}^\infty\mathcal N_d(\mu)x^{\mu}\right),\\ & = \mathcal G_1(x)\mathcal G_d(x),\end{aligned}\] and hence the claim follows by induction on \(d\). ◻
When discussing the applications of our main result, we will focus on nested sequences \(\mathcal S\) but note that the formulas \(\mathcal N_d(\mu)\) and \(\mathcal N^\Sigma_d(\mu)\) do not depend on the nestedness or non-nestedness of \(\mathcal S\). The general recipe for obtaining an expression for \(\mathrm N_d(\mu)\) or \(\mathcal N_d(\mu)\) consists in evaluating \(G_d\) and \(\mathcal G_d\) respectively and then – for the growth functions under consideration – one can use Newton’s binomial theorem and the Cauchy product in order read off \(\mathrm N_d(\mu)\) or \(\mathcal N_d(\mu)\). We will provide the details for the first three growth functions under consideration – the others being obtained similarly:
In this case, \(\displaystyle G_1(x) = \frac{n-1}{(1-x)(1-nx)},\) so that using Newton’s binomial theorem \[\begin{aligned} G_d(x) & = (n-1)^d\left(\frac{1}{1-nx}\right)^d\frac{1}{1-x},\\ & = (n-1)^d\left(\sum\limits_{k=0}^\infty\binom{d+k-1}{k}(n x)^k\right)\left(\sum\limits_{\ell=0}^\infty x^\ell\right). \end{aligned}\]
Reading off the coefficient of \(x^\mu\) using the Cauchy product yields \[\mathrm N_d(\mu) =(n-1)^d \sum\limits_{k=0}^\mu\binom{d+k-1}{k}n^k.\]
Remark 2.3. If \(n=2\), one can recover the formula given by [, Lemma] by exploting the fact that \[\binom{d-1+k}{k}=\binom{d-1+k}{d-1},\] and observing that there, the formula is stated for \(\mu-1\).
Smiliarly we obtain \[\begin{aligned} \mathcal G_d(x) & = (n-1)^d \left(\frac{1}{1-x}\right)^d\left(\frac{1}{1-nx}\right)^d,\\ & = (n-1)^d \left(\sum\limits_{k=0}^\infty \binom{d+k-1}{k}(nx)^k\right)\left(\sum\limits_{\ell=0}^\infty \binom{d+\ell-1}{\ell}x^\ell\right). \end{aligned}\]
The coefficient of the term \(x^\mu\) is therefore \[\mathcal N_d(\mu) = (n-1)^d\sum\limits_{k=0}^\mu \binom{d+k-1}{k}\binom{d+\mu-k-1}{\mu-k}n^k.\]
Here, \(\displaystyle G_1(x) = \frac{n}{1-nx},\) so that \[\begin{aligned} G_d(x) & = n^d \left(\frac{1}{1-nx}\right)^d(1-x)^{d-1},\\ & = n^d \left(\sum\limits_{k=0}^{d-1} \binom{d-1}{k}(-1)^kx^k\right)\left(\sum\limits_{\ell=0}^\infty\binom{d+\ell-1}{\ell}(n x)^\ell\right). \end{aligned}\]
Reading off the coefficient of \(x^\mu\) leads to \[\label{chebyshev_new} \mathrm N_d(\mu) =n^d\sum\limits_{k=0}^{\min\{d-1,\mu\}}\binom{d-1}{k}(-1)^k\binom{d+\mu-k-1}{\mu-k}n^{\mu-k},\tag{3}\] which can be shown to be equivalent to \[\label{chebyshev_new_2} \mathrm N_d(\mu) = \sum\limits_{k=0}^{\min\{d-1,\mu\}}\binom{d-1}{k}\binom{\mu}{k}n^{\mu+d-k}(n-1)^{k}.\tag{4}\]
Remark 2.4. 1. If one takes \(f(k)=n^{k-1}\) in (4), then one obtains the same result up to a factor \(n^d\) so that in this case, if \(n=2\), one obtains
\[\mathrm N_d(\mu) = \sum\limits_{k=0}^{\min\{d-1,\mu\}}\binom{d-1}{k}\binom{\mu}{k}2^{\mu-k},\] which equals exactly the formula found by [9].
2. Formula (4) with \(n=3\) gives an explicit expression for \(\mathrm N_d(\mu)\) for the case of a Smolyak-grid constructed with Chebyshev points of the first kind. If \(f(k)=3^{k-1}\) is used instead, one obtains the same formula up to a factor \(3^d\).
Similarly, \[\mathcal G_d(x) = n^d\left(\frac{1}{1-n x}\right)^d = n^d\left(\sum\limits_{k=0}^\infty \binom{d+k-1}{k}(nx)^k\right),\] so that the coefficient of \(x^\mu\) can be read off and one obtains \[\mathcal N_d(\mu) = n^{d+\mu}\binom{d+\mu-1}{\mu}.\]
Remark 2.5. This formula can be obtained in a much simpler way: If \(f(k) = n^k\) one has \[\mathcal N_d(\mu) = \sum\limits_{|\mathbf i|=d+\mu}n^{|\mathbf i|} = n^{d+\mu}\left.\left|\left\{\mathbf i\in \mathbb N_{\geqslant 1}^d\right| |\mathbf i|=d+\mu\right\}\right|,\] and the equality \[\left.\left|\left\{\mathbf i\in \mathbb N_{\geqslant 1}^d\right| |\mathbf i|=d+\mu\right\}\right|=\binom{d+\mu-1}{\mu},\] can be obtained using a stars and bars argument.
Here, \[\begin{aligned} G_1(x) =& \frac{n+1-2nx}{(1-x)(1-nx)}, \\ \mathrm N_d(\mu)=&\sum\limits_{k=0}^{\min\{d,\mu\}} \binom{d}{k}(-2n)^k(n+1)^{d-k} \sum\limits_{\ell=0}^{\mu-k}\binom{d+\ell-1}{\ell}n^\ell. \end{aligned}\]
Remark 2.6. Note that for the case \(n=2\) and \(f(k)=2^k+1\), a formula is already available in [2] which thinks of this case as upgrading the case of the growth function \(g(k)=2^k-1\) by two boundary points. Counting the \(j\)-skeleta of the \(d\)-dimensional hypercube yields \(\binom{d}{j}2^{d-j}\) for fixed \(j\). Then the formula for \(f\) is obtained by building the sum of the formula for \(g\) over all \(j\)-skeleta as \(j=0,\ldots, d\). This approach – for general \(n\) – yields the equivalent formula \[\mathrm N_d(\mu)=\sum\limits_{k=0}^{d} \binom{d}{k}2^{d-k}(n-1)^k\sum\limits_{\ell=0}^\mu \binom{k+\ell-1}{k-1}n^\ell.\]
Furthermore, in this case, \(\displaystyle \mathcal G_d(x) = (n+1-2nx)^d\left(\frac{1}{1-nx}\right)^d\left(\frac{1}{1-x}\right)^d,\) so that
\[\mathcal N_d(\mu) = \sum\limits_{\ell = 0}^{\min\{d,\mu\}}\sum\limits_{k=0}^{\mu-\ell} \binom{d}{\ell}(-1)^\ell (2n)^\ell(n+1)^{d-\ell}\binom{d+k-1}{k}\binom{d+\mu-\ell-k-1}{\mu-\ell-k}n^k.\]
Here, \(G_1(x) = \frac{1}{(1-x)^2}\) so that \(\displaystyle G_d(x) = \frac{1}{(1-x)^{d+1}}= \sum\limits_{k=0}^\infty \binom{d+k}{k}x^k,\) and hence \[\mathrm{N}_d(\mu) = \binom{d+\mu}{\mu}.\]
Similarly, we obtain \[\mathcal G_d(x) = \frac{1}{(1-x)^{2d}}= \sum\limits_{k=0}^\infty \binom{2d+k-1}{k}x^k,\] and hence \[\mathcal{N}_d(\mu) = \binom{2d+\mu-1}{\mu}.\]
In this case, we obtain setting \(m=\max\{0,\mu+1-d\}\): \[\mathcal{N}^{\Sigma}_d(\mu) =\frac{1}{2d}\left((1+\mu)\binom{2d+\mu}{\mu+1}-m\binom{2d+m-1}{m}\right).\]
If \(f(k) = 2^{k-1}+1\) for \(k>1\) and \(f(1)=1\), one can show by induction on \(d\) using (2) that \(\mathrm N_d(\mu)-1 = 2^{\mu} P_{d-1}(\mu),\) where \(P_{d-1}\) is a polynomial of degree \(d-1\) with leading coefficient \(1/({2^{d-1}(d-1)!})\) so that one obtains the asymptotics \[\mathrm N_d(\mu) \sim\color{black} \frac{2^{\mu}}{2^{d-1}(d-1)!}\mu^{d-1},\] for \(d\) fixed and \(\mu\to\infty\), compare [7, Lemma 1].
Using \(f(k) = 2k-1\) yields \(\displaystyle G_1(x) = \frac{1+x}{(1-x)^2},\) so that \(\displaystyle G_d(x) = \frac{(1+x)^d}{(1-x)^{d+1}},\) and hence \[\mathrm N_d(\mu) = \sum\limits_{k=0}^{\min\{d,\mu\}}\binom{\mu}{k}\binom{\mu+d-k}{\mu},\] which is precisely Theorem 2 of [8]. We note that this formula is also obtained using generating functions.
This study has been financed by the “Ingénierie et Architecture” domain of HES-SO, University of Applied Sciences Western Switzerland, which is acknowledged. We further thank the referees for their careful reading and their valuable comments and suggestions.