
At present, after more than ten years of development, evolution, and systematization, physical education teaching theory has begun to show the prototype of its discipline system [13,15]. It has developed its own discipline-specific terminology, research paradigms, and theoretical systems, and occupies an important position in the physical education discipline system. The research object of physical education theory is physical education [9,5], which is a subordinate concept of teaching [11]. Like other forms of teaching, physical education is an educational process that includes attributes such as imparting knowledge and skills.
With the rapid development of science and technology, the continuous introduction of new foreign physical education concepts and methods, and the country’s growing demand for educational reform, research in the field of physical education in China has become very active, yielding many important results. According to the analysis of foreign physical education research from 2004 to 2013 by scholars such as Gao Ming, it is evident that most of the current research in physical education globally comes from developed sports countries such as those in North America and Europe, where the research results dominate [11]. Therefore, the author believes that, at present, physical education in western countries, particularly the United States, has developed more successfully than in China, with more abundant and diverse research outcomes [3]. A comparative analysis of the physical education research fields in China and the United States reveals that there are many lessons to be learned from the development of physical education in the West [8,12].
Faced with these abundant research results, questions arise: What are the recent research hotspots in physical education teaching in China and the United States? What changes have been made in the research issues? What research results exist, and where will the research trends go? Addressing these questions will help grasp the direction of research in the field of physical education teaching in China and the United States, which is of great significance for the development of this field in China [12,1].
Currently, domestic research in the field of physical education teaching in China mainly focuses on the analysis of individual basic elements in physical education [10,2], while overall research in the field is relatively insufficient. Most of the research is centered around content analysis, research hotspots [4], status quo analysis [6], and trends [16], but comparative studies with foreign frontiers and hotspots remain scarce. As a result, it takes a lot of time for researchers to understand the existing research results both at home and abroad.
In today’s era of rapid informatization, where vast amounts of digital information are available, how to effectively mine and discover its characteristics and patterns has become one of the major research focuses in the field of scientometrics. The scientific knowledge graph is an emerging research method in this context. Based on the above situation, this paper proposes a visual analysis and comparison of physical education teaching in China and the United States from the perspective of a knowledge graph, hoping to provide some reference for scholars in the field of physical education teaching in the future.
Knowledge reduction is the core problem of rough set theory, and its essence is to eliminate irrelevant or unimportant redundant knowledge while maintaining the classification ability of the knowledge base. Typically, the knowledge reduction method of a knowledge base is not unique, and the complexity of computing knowledge reduction increases exponentially with the size of the decision table. Existing reduction algorithms mainly focus on the kernel of rough sets and use heuristic search methods to construct reductions with the least number of conditional attributes, known as minimum reductions. However, this algorithm is not applicable to all knowledge expression systems, and as the problem size increases, the complexity also increases. Genetic algorithms (GA) offer the advantages of global optimization and implicit parallelism, making them suitable for solving knowledge reduction problems [7,14].
Based on the analysis of the rough set knowledge reduction method, this paper proposes an improved genetic algorithm (IGA+RS) for rough set knowledge reduction. By incorporating the support and importance of conditional attributes to decision attributes as heuristic information, and introducing the concepts of population dissimilarity and individual dissimilarity, the proposed IGA+RS algorithm effectively improves the efficiency of knowledge reduction.
Rough set theory, introduced by Polish scholar Pawlak in 1982, is a mathematical framework for analyzing imprecise and uncertain information. It is widely used to extract decision or classification rules for various problems. Below, we provide an overview of rough set theory and its core concepts.
An information system (or information table) is denoted as \(S = \langle U, R, V, f \rangle\), where: – \(U\) is a non-empty finite set, called the universe. – \(R\) is a set of attributes, with \(R = C \cup D\), where \(C \cap D = \emptyset\), \(C\) is the set of condition attributes, and \(D\) is the set of decision attributes. – \(V\) is the value range of each attribute \(r \in R\). – \(f: U \times R \to V\) is an information function assigning a value to each attribute of each object.
This quadruple is also referred to as a decision system or decision table.
For an information system \(S = \langle U, R, V, f \rangle\) and a subset of attributes \(B \subseteq R\), the indiscernibility relation \(IND(B)\) is defined as: \[\label{e1} IND(B) = \{ (x, y) \mid x, y \in U, \forall b \in B, f(x, b) = f(y, b) \}. \tag{1}\] The relation \(IND(B)\) forms a partition of \(U\), denoted as \(U/IND(B)\), or simply \(U_B\). Each equivalence class in \(U_B\) represents a set of indistinguishable objects based on the attributes in \(B\).
For a subset \(X \subseteq U\) and indiscernibility relation \(B\), the lower approximation of \(X\) with respect to \(B\) is defined as: \[B(X) = \{ x \in U \mid [x]_B \subseteq X \}, \tag{2}\] where \([x]_B\) is the equivalence class containing \(x\). This set, also known as the positive region, contains objects that can be confidently classified into \(X\).
Given an information system \(S = \langle U, R, V, f \rangle\) and subsets \(P, Q \subseteq R\), the positive region of \(Q\) with respect to \(P\) is defined as: \[POS_P(Q) = \bigcup_{X \in U/Q} P(X), \tag{3}\] where \(U/Q\) represents the equivalence classes of \(Q\). The positive region includes all objects in \(U\) that can be definitively classified based on \(P\).
Let \(S = \langle U, R, V, f \rangle\), and \(P, Q \subseteq R\). An attribute \(K \in P\) is said to be \(Q\)-necessary in \(P\) if: \[POS_P(Q) \neq POS_{P – \{K\}}(Q). \tag{4}\] If every \(K \in P\) is \(Q\)-necessary, then \(P\) is \(Q\)-independent. Otherwise, \(P\) contains redundant attributes. The set of all \(Q\)-necessary attributes in \(P\) is called the \(Q\)-core, denoted as \(CORE_Q(P)\).
For \(S = \langle U, R, V, f \rangle\) and \(P, Q \subseteq R\), a subset \(P' \subseteq P\) is a relative reduction of \(P\) with respect to \(Q\) if: \[POS_{P'}(Q) = POS_P(Q) \quad \text{and} \quad P' \text{ is } Q\text{-independent}. \tag{5}\] The relative reduction is not unique, but the \(Q\)-core is the intersection of all relative reductions.
In the information system \(S = \langle U, R, V, f \rangle\), let \(C\) denote the condition attribute set and \(D\) denote the decision attribute set. If the partition of \(U\) induced by \(C\) is \(U/C = \{x_1, x_2, \dots, x_n\}\) and the partition induced by \(D\) is \(U/D = \{y_1, y_2, \dots, y_m\}\), the support of the condition attribute \(C\) to the decision attribute \(D\) is defined as:
\[\label{e2} SP_C(D) = \frac{1}{|U|} \sum_{i=1}^m \left| \operatorname{pos}_C(y_i) \right|, \tag{6}\] where \(y_i \in U/D\) and \(\operatorname{pos}_C(y_i)\) represents the positive region of \(y_i\) with respect to \(C\).
The value of \(SP_C(D)\) lies within the range \(0 \leq SP_C(D) \leq 1\). Specifically:
– \(SP_C(D) = 1\) indicates that the decision system is fully determined by the condition attributes, meaning all objects in \(U\) can be accurately classified into the equivalence classes of \(U/D\) using the knowledge provided by \(C\).
– \(SP_C(D) = 0\) implies that the decision information is entirely independent of the condition attributes, indicating that the knowledge \(C\) has no influence on the decision-making process.
A larger value of \(SP_C(D)\) indicates that the condition attribute set \(C\) enables more precise classification of objects into the equivalence classes of \(U/D\). This relationship can be expressed as follows: if \(E \subseteq F\), then \(SP_E(D) \leq SP_F(D)\).
In the information system \(S = \langle U, R, V, f \rangle\), different attributes \(x\) in the condition attribute set \(C\) contribute differently to the decision attribute set \(D\). The importance of an attribute can be defined as:
\[\label{e3} \operatorname{IMP}_{C – \{x_i\}}^D(x) = SP_C(D) – SP_{C – \{x_i\}}(D), \tag{7}\] where \(SP_C(D)\) denotes the support of the condition attribute set \(C\) to the decision attribute set \(D\), and \(SP_{C – \{x_i\}}(D)\) is the support after removing attribute \(x_i\) from \(C\).
For the special case where \(C = \{x\}\), the importance is given by:
\[\label{e4} \operatorname{IMP}_{C – \{x\}}^D(x) = SP_C(D). \tag{8}\]
Thus, the importance of an attribute \(x \in C\) to the decision attributes \(U/D\) is measured by the change in the support degree when \(x\) is removed from \(C\).
Additionally, the relative kernel of the condition attribute set can be defined as:
\[\label{e5} \operatorname{core}_D(C) = \{x \in C \mid \operatorname{IMP}_{C – \{x\}}^D(x) > 0\}. \tag{9}\]
The relative kernel represents the subset of attributes in \(C\) that have a positive impact on the decision attributes. This kernel can be utilized in the initialization phase of genetic algorithms to accelerate their convergence.
To accelerate the convergence of the genetic algorithm, this study proposes an improved genetic algorithm based on rough set theory to identify the minimal reduction in decision-making problems. Specifically, it aims to find the attribute set with the fewest conditional attributes among all relative reductions. The implementation and improvement of the genetic algorithm are carried out in the following aspects.
The key operating parameters in a genetic algorithm include population size (\(M\)), crossover probability (\(P_c\)), and mutation probability (\(P_m\)). The commonly used parameter ranges are: \[\begin{aligned} M & = 20 – 100, \\ P_c & = 0.5 – 1.0, \\ P_m & = 0.0001 – 0.05. \end{aligned}\]
Another critical parameter is the termination condition, which determines whether the population has stabilized and no longer exhibits evolutionary progress. Two common criteria for this are:
The difference in the optimal fitness value between successive generations is less than a specified minimum threshold.
The variance of fitness values across the entire population is below a specified minimum threshold.
In the proposed \(IGA+RS\) algorithm, the termination condition is defined such that the difference in the optimal fitness values of successive generations is below a specified minimum threshold. This approach approximates the optimal solution efficiently.
The fitness function serves as the sole deterministic metric for evaluating individual bit strings in the genetic algorithm. According to the definition of attribute reduction, the fitness of an individual is influenced by two factors:
1. The number of attributes it contains: The number of “1”s in the chromosome represents the number of attributes. Fewer attributes increase the likelihood of selection.
2. The attribute’s ability to distinguish: The greater the number of instances distinguished by the chromosome, the higher its likelihood of being selected.
The fitness function is defined as:
\[\label{e6} F(x) = f(x) + \beta \cdot H(x) = \frac{1 – \operatorname{card}(x)}{\operatorname{card}(C)} + \beta \cdot \frac{\operatorname{card}\left({\operatorname{pos}_x(D)}\right)}{\operatorname{card}\left({\operatorname{pos}_\imath(D)}\right)}, \tag{10}\] where,
– \(f(x)\) is the objective function, representing the proportion of attributes excluded from individual \(x\).
– \(\operatorname{card}(x)\) is the number of “1”s in \(x\).
– \(\operatorname{card}(C)\) is the total number of conditional attributes in \(C\).
– \(H(x)\) is the penalty function, and \(\beta\) is the penalty factor.
– \(H(x)\) represents the ratio of the conditional attribute \(C\) to the decision attribute \(D\) in the individual.
The goal of \(f(x)\) is to minimize the number of conditions in \(x\), while \(H(x)\) aims to ensure that the conditions in \(x\) adequately support decision-making. Together, these components allow the fitness function to achieve optimal results in the attribute reduction problem.
For a given population of size \(m\), the selection probability of an individual is calculated as:
\[P_i = \frac{F(i)}{\sum_{i=1}^m F(i)}, \tag{11}\] where selection is performed using the roulette-wheel method.
Population diversity is a critical measure of the evolutionary state of a genetic algorithm. To optimize the crossover operation, both population dissimilarity and individual dissimilarity are defined. The degree of similarity between individuals \(x\) and \(x'\) is given by:
\[x = \{x_{11}, x_{12}, \dots, x_{1L}\}, \quad x' = \{x_{j1}, x_{j2}, \dots, x_{jL}\},\] where \(x_{lk}, x_{jk} \in \{0,1\}\) for \(k = 1, 2, \dots, L\), and \(L\) is the length of the individual string.
The dissimilarity between individuals \(x\) and \(x'\) is defined as:
\[ds(x, x') = \sum_{k=1}^L x_{ik} \oplus x_{jk},\] where \(ds(x, x')\) represents the number of differing genes between \(x\) and \(x'\). A larger \(d(x, x')\) implies lower correlation and reduces the likelihood of invalid operations during crossover.
For a population of size \(m\), the population dissimilarity is defined as:
\[\label{e7} DS = \frac{\sum_{i=1}^m \sum_{j=1, j \neq i}^m ds(x_i, x_j)}{m \cdot (m-1) \cdot L} \times 100\%. \tag{12}\]
As the genetic algorithm evolves, population dissimilarity decreases. Random pairing may lead to invalid inheritance, where offspring are identical to parents. To address this, a dissimilarity-based pairing algorithm is employed:
Sort individuals by fitness values in descending order.
Select the individual with the highest fitness, \(x\). Pair \(x\) with the individual \(x'\) having the maximum dissimilarity \(d(x, x')\).
Remove \(x\) and \(x'\) from the pool. If no individuals remain, pairing ends. Otherwise, repeat Step 2.
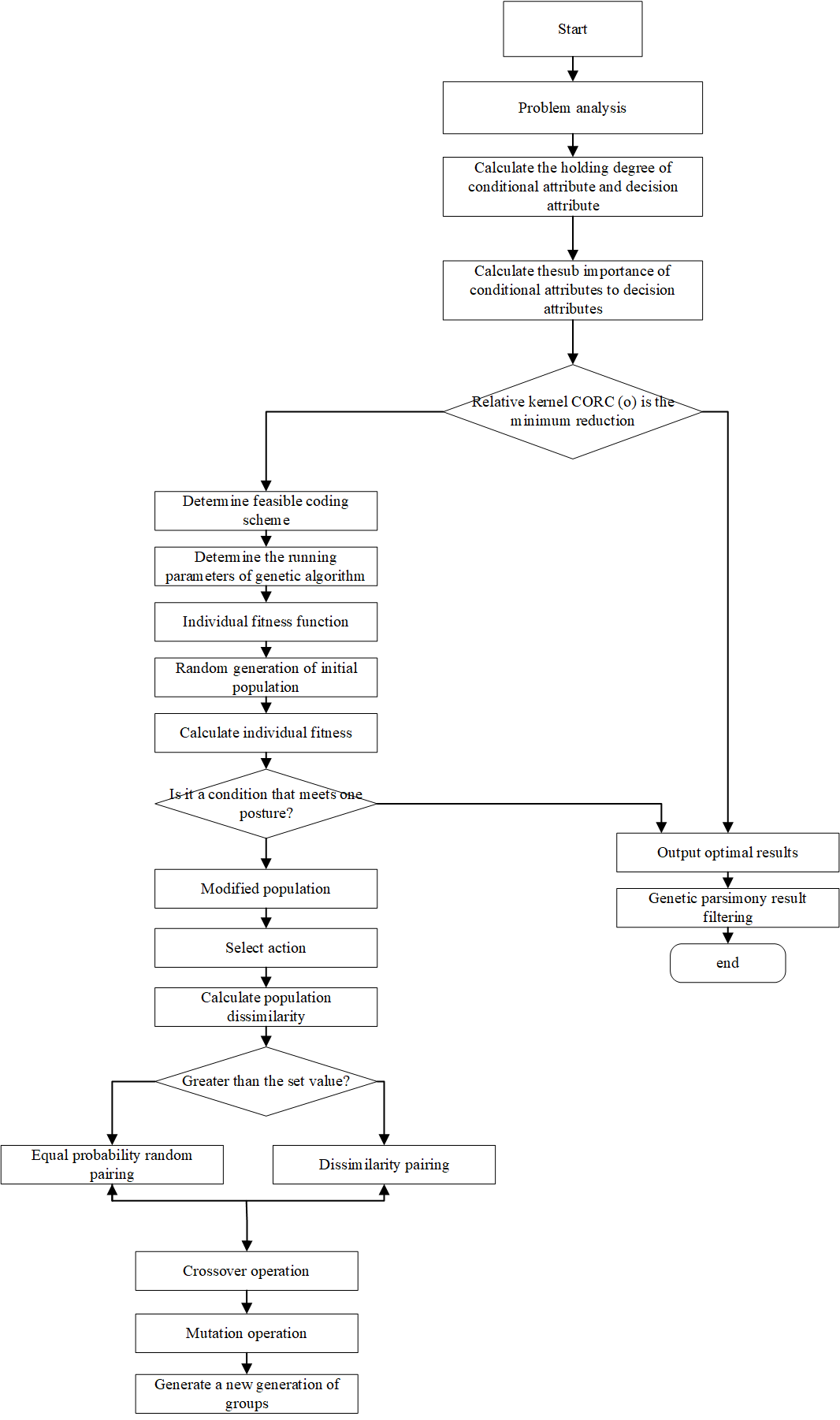
In this paper, the support and importance of condition attributes to decision attributes are introduced into the genetic algorithm as heuristic information. The algorithm flow of the IGA+RS algorithm is shown in Figure 1.
The IGA+RS algorithm first calculates the support and importance of the condition attribute set \(C\) to the decision attribute set \(D\). Specifically:
1. Compute the support \(SP_C(D)\) of the condition attribute \(C\) to the decision attribute \(D\) using Eq. (6).
2. Calculate the importance \(MMP_{C – \{x\}}^D(x)\) of each attribute \(x \in C\) to the decision attribute set \(D\) according to Eq. (7).
Let the relative core of \(C\) with respect to \(D\) be defined as:
\[{\operatorname{core}_D}(C) = \emptyset.\]
If \(MMP_{C – \{x\}}^D(x) \neq 0\), then \({\operatorname{core}_D}(C)\) is the minimum reduction of \(C\) relative to \(D\). In this case, the calculation terminates, yielding the optimal result. Otherwise, the IGA is executed to obtain the optimal result. The detailed algorithm flow is illustrated in Figure 1.
This paper uses CiteSpace V (version 5.1.R8) to analyze the co-citation network knowledge graph of 946 documents from 2012 to 2016. The parameters used include Years Per Slice in Time Slicing set to 1, Top \(N\) set to 50, and Visualization defaults set to Cluster View-Static with Show Merged Network enabled. The threshold values are set as \((2,2,20), (4,3,20), (4,3,20)\). Running the analysis generates the document co-citation network graph, which includes 256 nodes and 699 connections. Based on the co-citation network, the literature co-citation cluster knowledge map is obtained through clustering and cluster naming (proposed by Title), as shown in Figure 2.
A total of 39 clusters were formed in the clustered knowledge graph of the frontiers of physical education research in the United States. Among them, the 8 clusters with the largest areas are #0, #1, #2, #3, #4, #5, #9, and #10, as shown in Table 1. These clusters reflect the major research fronts in the field of physical education teaching research in the United States.
| Cluster Number | Size | Outline | Clustering Keywords |
| #0 | 39 | 0.941 | Practice-Based Model |
| #1 | 34 | 0.902 | Physical Activity Items |
| #2 | 32 | 0.765 | Sports Courses |
| #3 | 32 | 0.857 | Quantitative Study |
| #4 | 29 | 0.812 | Prospective Cross-Cutting Survey |
| #5 | 18 | 0.961 | Preservice Teacher Education |
| #9 | 6 | 0.973 | Role of Teachers |
| #10 | 6 | 0.969 | Self Achievement Goal |
As shown in Figure 2, the cluster names of the 8 clusters reflecting the main research frontiers in the field of physical education teaching in the United States are:
#0: Models-Based Practice,
#1: Physical Activity Program,
#2: Adventure-Physical Education Lesson,
#3: Quantitative Findings,
#4: Prospective Cross-Domain Investigation,
#5: Initial Teacher Education,
#9: Teachers Support, and
#10: Self-Reported Achievement Goal.
The main research front area #0 includes 39 cited literatures spanning 2006–2015. Eight key documents represented by nodes are listed in Table 2. These documents cover topics such as physical education teachers’ professional development, physical education models, reforms, teaching methods, and cooperative learning in sports. Among the 19 citing documents, 11 exhibit a citation activity of \(\geq 0.05\), as shown in Table 2.
| U | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | d |
| U1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 |
| U2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 2 | 21 | 2 |
| U3 | 1 | 1 | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 2 |
| U4 | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 3 |
| U5 | 1 | 2 | 2 | 2 | 2 | 1 | 3 | 2 | 2 | 2 |
| U6 | 2 | 2 | 2 | 1 | 2 | 1 | 3 | 2 | 3 | 1 |
| U7 | 1 | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 |
| U8 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 1 |
| U9 | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 2 | 2 |
| U10 | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 1 |
Take the population size \(M = 50\), \(P = 0.6\), \(P_m = 0.03\), \(B = 1.5\), and perform 30 random runs on the general reduced genetic algorithm and the JGA+RS algorithm. The results are shown in Table 3.
| Algorithm | Minimum Convergence Algebra | Attribute Reduction Set | Average Operation Time |
| General Reduction Genetic Algorithm | 15 | \(\left\{ C_1, C_2, C_5, C_7 \right\}\)) | 1034ms |
| IGA+RS Algorithm | 8 | \(\left\{ C_1, C_2, C_6, C_7 \right\}\)) | 629ms |
The experimental results in Table 3 demonstrate that the IGA+RS algorithm is correct and effective. Compared with the general reduction genetic algorithm, it operates faster, converges better, and more effectively achieves the minimum reduction.
The scientific knowledge graph is an emerging research method that provides new insights into this context. This paper proposes a rough set knowledge reduction algorithm based on an improved genetic algorithm. The support and importance of conditional attributes to decision-making attributes are introduced into the information system and integrated into the genetic algorithm as heuristic information. Additionally, the concepts of population dissimilarity and individual dissimilarity are proposed to enhance the genetic algorithm. The study finds that physical education teaching research in China tends to focus on problem-oriented research, while research in the United States emphasizes student health. By starting from the basic concept of an information system, this paper introduces the support and importance of conditional attributes to decision-making attributes as heuristic information into the genetic algorithm and proposes the IGA+RS algorithm for knowledge reduction. The experimental results demonstrate that the IGA+RS algorithm is an effective knowledge reduction method. It can significantly improve the efficiency of rough set knowledge reduction, offering both speed and effectiveness. In future research, this algorithm could be applied to the reduction of mass production data, which would have certain guiding significance for optimizing production operations.
This work was sponsored in part by Hunan Provincial Department of Education Scientific Research Project (23B1032).