
Mango weaving is a traditional handicraft of Bobai County, Guangxi, with flexible and changeable shapes, unique and beautiful samples, which can be used as practical tools for production activities or as embellishments for cozy homes, and has both practical and ornamental values. Mang weaving skill belongs to the intangible cultural heritage, and its inheritance demonstrates Guangxi’s characteristic culture and superior traditional skills, and also carries the values represented by the local history and culture, which is a part of China’s ancient excellent traditional culture. However, after entering the modern industrial society, with the rapid development of commodity economy and the change of people’s production and life style, Guangxi’s mango weaving skill, which originated from the traditional farming society, is facing the dilemma of shrinkage and decline.
With the rapid development of artificial intelligence technology, the inheritance and innovation of intangible cultural heritage have been revitalized like never before [12,15]. In terms of the protection and inheritance of intangible heritage, artificial intelligence technology is gradually realizing the comprehensive automated collection, organization and optimization of data related to intangible heritage [13,4,5]. Through image recognition, voice recognition and other cutting-edge technological means, it is possible to quickly capture all kinds of information on the scene of non-legacy activities, and build up a huge data system [16,2,9]. The application of natural language processing technology further transforms these data into a structured resource base, providing rich and valuable information for teaching NRL [3,10,17,7,1]. Artificial intelligence technology not only greatly enhances the attractiveness of non-heritage, but also enables the audience to more intuitively feel the deep historical and cultural heritage contained in non-heritage, and thus cherish and pass on these valuable cultural heritages even more [14,6,11,8]. Therefore, it is important to actively embrace advanced scientific and technological means to explore new development ideas and product development paths of the mango weaving craft to meet the current social changes and popular aesthetic needs, with a view to contributing to the integration of mango weaving products into modern life and realizing the sustainable development of the mango weaving craft.
On the basis of exploring the application of AI technology in the protection and innovation of mang weaving, the study utilizes data mining technology and model construction to analyze the communication development and innovation design for mang weaving skills. Crawling the review text of mango weaving products, we conduct in-depth mining of online reviews of mango weaving products based on the LDA model and text sentiment analysis method to analyze the perceived value and perceived sentiment of mango weaving product consumption from the dimensions of emotion, society, quality and price, so as to provide certain references for the development of mango weaving products. Then we design a lightweight generative adversarial network based on the non-local attention mechanism by embedding a non-local self-attention structure to obtain global semantic information and detailed features, and using the obtained information to encode step by step to generate the final more reasonable image. Two experimental datasets are selected, and the IS value and FID value are used as the evaluation indexes, and the comparison experiments of model performance and the mangaka design experiments are carried out in turn to explore the practical utility of the text-generated image model of this paper in the innovation of mangaka design.
Mang weaving is one of the traditional handicrafts of ethnic minorities in Guangxi, which is the crystallization of the wisdom of the people of Guangxi for thousands of years, and is also an important national cultural heritage of Guangxi. However, after entering the modern industrial society, with the rapid development of the commodity economy and the change of people’s production and life style, the traditional farming society of Guangxi’s mango weaving crafts are facing the dilemma of shrinkage and decline. In the intelligent era, the use of AI technology to digitally protect, pass on and disseminate the traditional skills of mango weaving will inevitably become a requirement for the protection of non-heritage at the local level. The digital protection and innovation of mang weaving skills based on AI is shown in Figure 1, and the specific paths of the integration of mang weaving skills and intelligent technology are as follows.
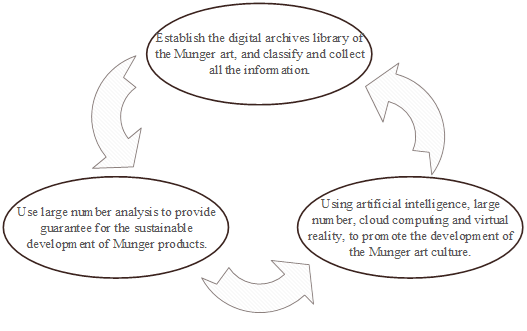
The production process of mango weaving is complex, and each step of the process requires the accumulation of experience and the use of skills. In the past, craftsmen who mastered the art of making mango weaving recorded the essentials of production through oral or written records, but now digital technology can be utilized to make a more comprehensive and detailed record. High-definition video technology can clearly record the whole process of the craftsmen’s production of mango weaving, and 3D scanning technology can utilize relevant software to scan the structure of mango weaving in multiple directions, and carry out 3D reconstruction calculations on the collected data, so as to create 3D digital models of mango weaving-related products in the virtual world. The production process of mango weaving and related product indexes recorded by digital means can be properly preserved, and a digital archive of mango weaving skills can be established to categorize, organize and systematically store all the information, so as to provide a powerful guarantee for subsequent study and research and publicity and promotion.
The more flexible and personalized development of the culture of mang weaving skills is promoted through the use of artificial intelligence technology in order to facilitate the development of a more adaptive communication environment, which is also conducive to expanding the ways and means of digitally disseminating mang weaving skills and reducing the negative impacts that may be generated in the process of digitization. The dissemination and presentation of mang weaving skills and culture can be better supported and promoted through the introduction of digital technology integration, such as artificial intelligence, big data, cloud computing and virtual reality. For example, the use of artificial intelligence technology can realize automatic translation and voice synthesis of the Mangweave skill culture, so that the Mangweave skill culture can be better disseminated all over the world. The use of big data technology can be used to analyze and mine the data of mango weaving skills and culture, to gain a deeper understanding of the connotation and characteristics of mango weaving skills, and to provide better support for the inheritance and innovation of mango weaving skills. Virtual reality technology can be used to create a virtual exhibition hall, so that people can learn about the culture of mang weaving skills through virtual reality technology in an immersive way.
In the digital era, big data analysis can provide precise assistance for the development of the industry. Through the use of big data technology, it can efficiently grasp market dynamics, consumption trends, customer needs and other content. Big data analysis should be well utilized to provide a guarantee for the sustainable development of mang weaving-related cultural and creative products.
In the conceptualization of mango weaving products, big data analysis can be used to screen out consumer groups interested in traditional culture, non-heritage skills and handicrafts, classify them as target customer groups, and further understand their age, gender, region, consumption habits, aesthetic tendencies and other information, so as to customize attractive mango weaving products on the basis of an in-depth analysis and an accurate grasp of customer needs. In the design process, big data analysis can be used to find the inspiration collision of cross-border cooperation, and actively discover the potential connection and complementary relationship between different fields. For example, fashion, technology and other diversified elements can be integrated into the design of mango weaving products to find the right fit and create new products with a traditional flavor without losing the sense of modernity. Entering the production process, we can analyze the user feedback data of the past products to know how consumers really feel about the products, so that we can optimize the product performance and improve customer satisfaction by making up for the “short board”. At the same time, AutoCAD design software, 3D printing technology and other digital tools can also be used to assist the R & D and innovation of mango knitting products, thereby effectively improving design efficiency and product creativity.
Based on this analysis, the following section will use intelligent algorithms to analyze the review text of mango weaving products and construct an image generation model to output mango weaving design images, which will support the protection of mango weaving techniques and innovative design.
Based on the analysis of the application of AI technology in the digital preservation and innovation of mango weaving skills, this chapter combines big data technology and the theory of perceived value to analyze the consumer reviews of mango weaving products by using the LDA model, so that the craftsmen can adjust the production and dissemination process of the mango weaving products according to the feedback, which is conducive to the preservation and development of the mango weaving skills.
The LDA model is a generative statistical model that is widely used to deal with topic discovery problems. In general, LDA model can better disambiguate words and assign documents and topics more accurately, and it is easier to scale large data on a computing cluster using MapReduce method. In addition, LDA, as an unsupervised machine learning algorithm, is mainly based on a three-layer Bayesian probabilistic model of “document-topic-vocabulary”, where the topics are polynomial probability distributions of the documents and the vocabulary are polynomial probability distributions of the topics, and iterative estimation can be used to extract the implicit topic information in a large text set or a corpus.
In the LDA model, \(\alpha\) is the prior parameter for topics, which refers to the Dirichlet distribution of topics within document \(D\). \(\beta\) is the prior parameter of words, which refers to the Dirichlet distribution of words within topic \(\omega\). \(\theta _{i}\) is the posterior parameter for topics, which refers to the distribution probability of each topic in document \(i\). \(\phi _{t}\) is the word’s posterior parameter, referring to the distribution probability of each word within topic \(t\).
The number of topics needs to be determined first before topic modeling. In the LDA theme model, the number of themes K value for the model has a crucial role, directly affecting the quality of the theme. If the number of topics K is too small, the final topic words will be too broad, and it is difficult to accurately map the key content of the text data. On the contrary, if the number of topics K is too large, it will lead to a long training time for the model, and at the same time, it will lead to a sparse distribution of topics, resulting in the topic can not constitute a system.
When evaluating LDA models, two evaluation methods, confusion and similarity, are commonly used. In this paper, we synthesize the existing methods and choose to use the calculation of the perplexity degree to determine the number of topics in the text of the mangled product reviews in each time period. In the field of information theory research, perplexity is an important indicator used to measure the effectiveness of probabilistic models in predicting samples. In general, low perplexity indicates that probability distributions deal with predicting samples better.
Perplexity is an important metric in the field of natural language processing for evaluating a language model, which is the probability distribution of utterances or texts. The formula of perplexity is shown in Eq. (1): \[\label{GrindEQ__1_} \text{Perplexity}\left(D\right)=\exp \left(\frac{\sum\limits_{m=1}^{M}\log _{P} \left(w_{m} \right)}{\sum\limits_{m=1}^{M}N_{m} } \right) . \tag{1}\]
In Eq. (1), the denominator \(\sum\limits_{m=1}^{M}N_{m}\) represents the sum of all words in the data set, which refers to the total length of the data set, and \(P\left(w_{m} \right)\) refers to the probability of occurrence of each word in the data set, as shown in Eq. (2): \[\label{GrindEQ__2_} P\left(w\right)=p\left(z\left|d\right. \right)p\left(w\left|z\right. \right) . \tag{2}\]
In Eq. (2), \(p\left(z\left|d\right. \right)\) represents the probability of occurrence of each topic in a document, and \(p\left(w\left|z\right. \right)\) represents the probability of occurrence of each word in a dictionary under a certain topic.
The fluctuation trend of the distribution curve of “perplexity – number of topics” is related to the number of topics K, in which the value of turning points reflects the generalization ability of the topic model to some extent, and the optimal number of topics can be roughly estimated according to these turning points. In this paper, we will determine the number of topic identification based on the distribution curve of “confusion degree – number of topics” obtained from text data in each time period.
The basic idea of the Gibbs sampling algorithm is to obtain \(K\) each sample \(X=\left(X_{0} ,X_{1} ,X_{2} ,X_{3}\right. ,\ldots ,\) \(\left.X_{N} \right)\) from a joint distribution probability \(P\left(X_{0} ,X_{1} ,X_{2} ,X_{3} ,\ldots ,X_{N} \right)\), process each variable through a random initialization to obtain \(X^{\left(0\right)}\), compute the sample \(X^{\left(i\right)}\) through \(i=1,2,3,\ldots K\), and sample the variable \(X_{j}\) from a conditional distribution probability \(P\left(X_{j}^{(i)} \left|X_{j-1}^{(i)} \right. ,X_{j+1}^{(i-1)} ,\ldots ,X_{j}^{(i-1)} \right)\).
The Gibbs sampling algorithm starts from an initial dimension value and multiplies it by the transfer matrix to get a new dimension value, then iterates the process for several times until the obtained result stabilizes and outputs the result to be estimated, the specific sampling formula is shown in Eq. (3): \[\label{GrindEQ__3_} P\left(Z_{i} =K\left|Z_{i-1} \right. \right)\propto \frac{\left(n_{k-1}^{(i)} +\beta _{i} \right)\left(n_{d-i}^{(k)} +\alpha _{k} \right)}{\sum\limits_{i-1}^{V}\left(n_{k-1}^{(i)} +\beta _{i} \right) } . \tag{3}\]
Also the posterior probability distribution of the subject vocabulary and hyperparameters can be written as: \[\label{GrindEQ__4_} P\left(z,w\left|\alpha \right. ,\beta \right)=\prod _{z=1}^{T}\frac{\Delta \left(n_{z} +\beta \right)}{\Delta \beta } *\prod _{d=1}^{D}\frac{\Delta \left(n_{d} +\alpha \right)}{\Delta \alpha } . \tag{4}\]
According to Eq. (4) the posterior distribution probabilities of topics and words can be calculated.
When the result obtained by using Gibbs sampling algorithm for solving tends to be stable, according to the convergence of the probability of all words except the current word under each topic can be calculated \(\theta _{d}\) and \(\varphi _{z}\), and finally get the topic probability distribution and vocabulary probability distribution of the text, which are calculated as shown in Eq. (5) and Eq. (6): \[\label{GrindEQ__5_} \theta _{dz} =\frac{n_{d}^{Z} +\alpha }{\sum\limits_{z=1}^{Z}n_{d}^{Z} +\alpha } , \tag{5}\] \[\label{GrindEQ__6_} \varphi _{z,i} =\frac{n_{z}^{i} +\beta }{\sum\limits_{i=1}^{V}n_{z}^{i} +\beta } , \tag{6}\]
In this study, the review texts of mangled products on relevant platforms are used as sample data, and Goo Seeker and Octopus are used for review crawling. In order to ensure the quality of the data, cleaning removes the text with length less than 5, content duplication and semantic duplication, and obtains 3517 valid reviews. Use Jieba Segmentation Tool to perform Chinese segmentation processing on the comment text data.
| Perceptual dimension | Number | Topic type | High frequency word | Probability |
| Emotional value | 1 | Appearance design | Beautiful, exquisite, design, pretty, atmosphere, small, beautiful, aesthetics, size | 0.227 |
| Functional quality | 2 | Quality work | Quality, exquisite, texture, material, feeling, structure | 0.212 |
| Emotional value | 3 | Cultural connotation | Meaning, refinement, imagination, culture, perfection, meaning, happiness, tradition | 0.194 |
| Functional price | 4 | Product price | Price, suitable, cost-effective, effective, cheap, affordable, characteristic, style and preferential treatment | 0.186 |
| Social value | 5 | Social interaction | Friends, gifts, birthday gifts, meaning, interesting, gift box, heart, family | 0.181 |
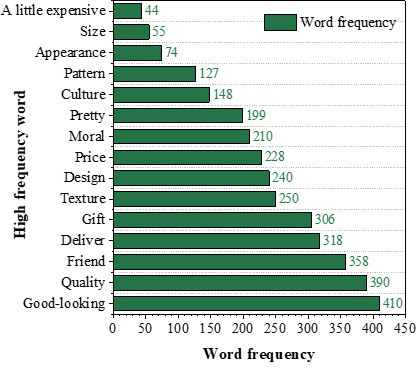
In the emotional value dimension, consumers pay the most attention to the pursuit of aesthetics, so a large number of words describing the appearance design of mango weaving products appear, such as good-looking, exquisite, and beautiful. In addition, the storytelling of mango weaving products, i.e., the cultural connotations embedded in them, also receives a certain amount of attention, with high-frequency words such as moral, culture, and ruyi reflecting consumers’ perceptions of the cultural significance and values attached to mango weaving products.
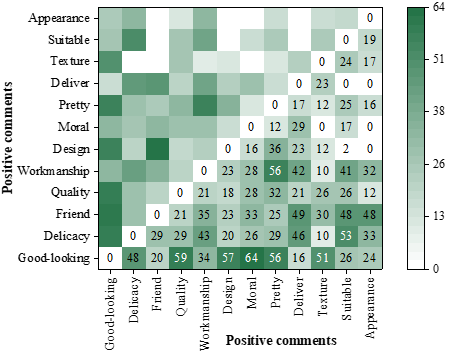
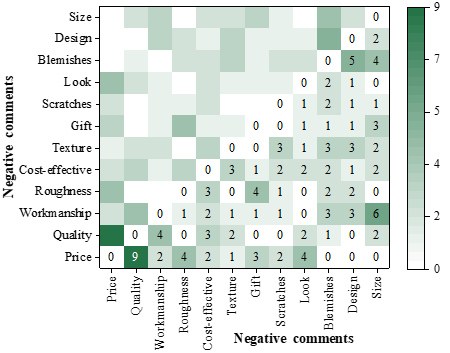
The co-occurrence matrix of negative review words for Mango Editor products is shown in Figure 5. The frequency of co-occurrence of negative review words of mango knitting products ranges from 0 to 9. The word co-occurrence matrix of negative texts indicates that consumers’ negative emotions mainly stem from the basic attributes of the product and the dimensions of functional quality and functional value. First, the pricing of mango knitting products is questioned, with a high co-occurrence of price and quality, reflecting that some consumers believe that mango knitting products are not worth the current pricing. Second, some consumers’ negative emotions are related to the workmanship of mango-woven products. The high frequency of co-occurring words such as roughness, scratches, defects, and size indicate that some consumers are disappointed with the quality of the mango weaving products they purchased.
Based on AIGC technology, natural language is used to describe keywords, generate graphics, and obtain their effects, which can quickly present a wide range of possibilities for selection and optimization. At the same time, AIGC’s powerful learning ability generates multiple styles of content from the descriptions and precisely feeds back to the viewer, thus stimulating the viewer’s creative thinking. This chapter constructs a text-generated image model and applies it to generate innovative content for the mango weaving technique, which facilitates the innovative design and development of traditional mango weaving craft products.
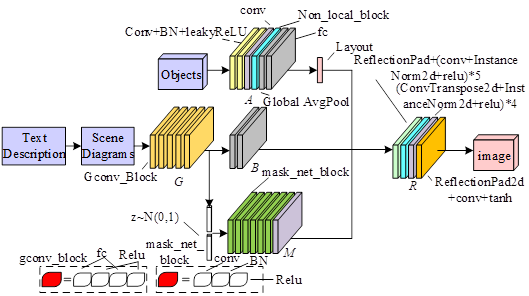
In order to improve the computational efficiency to generate high quality images, this paper builds a model based on generative adversarial network for text-to-multi-target image generation in terms of model structure design.
The network consists of several subcomponents:(1) Graph Convolutional Network (G), which is responsible for converting the input scene graph into embedding vectors for each object based on their positions. (2) Convolutional neural network (M), which is responsible for converting the layout embedding vectors and random embedding vectors of the objects into the corresponding masks. (3) A parallel network (B), which is responsible for converting the layout embedding vectors of an object into bounding box positions. (4) An appearance decoder (A), responsible for converting the image information into the corresponding embedding vectors. (5) An encoder-decoder network (R), responsible for generating the final image.
In the nonlocal self-attention module, \(c\) denotes the number of channels, and \(h\), \(w\) denote the height and width of the feature map respectively. \(X\) is a feature map with shapes \(\left[bs,c,h,w\right]\), \(bs\) i.e., batch sizes, which first undergoes three \(1\times 1\) convolution operations and flattening operations, the former of which changes \(c\) into half of its original size, and the latter of which changes \(h\), \(w\) into \(h\times w\), to obtain a tensor of \(\left[bs,{c\mathord{\left/ {\vphantom {c 2}} \right. } 2} ,h\times w\right]\). The tensor corresponding to \(\theta\) is subjected to channel rearrangement, also known as transposition in linear algebra, to obtain a tensor of shape \(\left[bs,h*w,{c\mathord{\left/ {\vphantom {c 2}} \right. } 2} \right]\), which is then matrix multiplied with the tensor represented by \(\phi\) to obtain a tensor of shape \(\left[bs,h\times w,h\times w\right]\). After that the operations of normalization and matrix multiplication are performed respectively, here normalization is done using softmax, flattening and transposing \(f\) and \(g\), then matrix multiplication is performed to get a tensor of shape \(\left[bs,h\times w,{c\mathord{\left/ {\vphantom {c 2}} \right. } 2} \right]\) and transposed to a tensor of shape \(\left[bs,{c\mathord{\left/ {\vphantom {c 2}} \right. } 2} ,h\times w\right]\), and finally the \(h\times w\) dimensions are re-converted to \(\left[h,w\right]\), which results in a tensor of shape \(\left[bs,{c\mathord{\left/ {\vphantom {c 2}} \right. } 2} ,h,w\right]\). A \(1\times 1\) convolution operation is used again on this tensor and the original channel size is restored, which gives the tensor of \(\left[bs,c,h,w\right]\). Finally \(X\) is added to the resulting tensor. This can be expressed as in Eq: \[\label{GrindEQ__7_} y_{i} =\frac{1}{C\left(x\right)} \sum\limits_{\forall ji}f \left(x_{i} ,x_{j} \right)g\left(x_{j} \right) . \tag{7}\]
In the above equation, the input is \(x\), the output is \(y\), \(i\) and \(j\) represent some spatial location of the input respectively, \(x_{i}\) is a vector with the same number of dimensions as the number of channels of \(x\), \(f\) is a function that computes the similarity relation between any two points, and \(g\) is a mapping function that maps a point to a vector, which can be viewed as computing the features of a point. \(C\left(x\right)\) is a normalization factor.
For the sake of concise representation, the \(g\) function can be viewed as a linear transformation can be viewed as a linear transformation formula as follows: \[\label{GrindEQ__8_} g\left(x_{j} \right)=W_{g} x_{j} , \tag{8}\] where \(W_{g}\) is the weight matrix to be learned, which can be realized by \(1\times 1\) convolution on the space.
The \(f\) function is a function used to compute the similarity of \(i\) and \(j\), which is denoted by the specific formula: \[\label{GrindEQ__9_} f\left(x_{i} ,x_{j} \right)=e^{x_{i} x_{i} } , \tag{9}\] and \(C\left(x\right)\) is denoted as: \[\label{GrindEQ__10_} C\left(x\right)=\sum\limits_{\forall j}f \left(x_{i} ,x_{j} \right) . \tag{10}\]
Reconstruction loss \(l_{r}\) is the L1 difference between the reconstructed image and the real image. Frame loss \(l_{b}\) is the MSE difference between the predicted frame and the real frame. Perceptual loss \(l_{p}\) is used to compare the generated image with the real image and the loss function is shown below: \[\label{GrindEQ__12_} \ell _{p} =\sum\limits_{s\in s}\frac{1}{S} \left\| F^{s} \left(I\right)-F^{s} \left(I\right)\right\| _{1} , \tag{12}\] where \(I\) denotes the real image, \(I{'}\) denotes the generated image, \(F^{s}\) is the excitation of layer \(u\) of the pre-trained VGG19 network, and \(S\) denotes the set of \(s\).
In this paper, three discriminators are used and the first discriminator \(D_{mask}\) is LS-GAN with the following loss function: \[\label{GrindEQ__13_} \ell _{D-mask} =\log D_{mask} \left(m'_{i} ,k_{i} \right)+{\mathop{E}\limits_{z\sim N(0,1)^{64} }} \left[\log \left(1-D_{mask} \left(M\left(s_{i} ,z\right),k_{i} \right)\right)\right] , \tag{13}\] where \(m_{i} {'}\) is the true mask of object \(i\), \(m_{i}\) is the generated mask, \(k_{i}\) denotes the category of the object, z is a random vector, and M is the convolutional neural network mentioned above, which is responsible for converting the layout embedding vectors and random embedding vectors of the object into the corresponding masks.
The second discriminator \(D_{img}\) is used to train three networks, i.e., \(R\), \(M\) and \(A\) as mentioned above. The loss function for \(D_{img}\) is shown below: \[\label{GrindEQ__14_} \ell _{D-img} =\ell _{t} -\ell _{f-img} -\ell _{f-layout} +\ell _{alt-appearance} . \tag{14}\]
Among them: \[\label{GrindEQ__15_} \ell _{t} =\log D_{img} \left(t,I\right) , \tag{15}\] \[\label{GrindEQ__16_} \ell _{f-img} =\log \left(1-D_{img} \left(t,I\right)\right) , \tag{16}\] \[\label{GrindEQ__17_} \ell _{f-turyout} =\log \left(1-D_{img} \left(t,I{'} \right)\right) , \tag{17}\] \[\label{GrindEQ__18_} \ell _{alt-appecrance} =\log \left(1-D_{img} \left(t{'} ,I{'} \right)\right) , \tag{18}\] where \(t{'}\) denotes the true layout tensor, \(t\) denotes the generated layout tensor, and \(t''\) denotes the fake layout tensor, but different from \(t\).
The third discriminator is \(D_{obj}\), which makes the generated object real. Its loss function is shown as follows. \[\label{GrindEQ__19_} \ell _{D-obj} =\sum\limits_{i=1}^{n}\log D_{obj} \left(O_{i} \right)-\log D_{obj} \left(O_{i} \right) , \tag{19}\] where \(O_{i} {'}\) is the object cropped from the real image based on the real bounding box and \(O_{i}\) corresponds to it.
\(l_{FM-mask}\), \(l_{FM-img}\) are similar to the perceptual loss in that they are based on the L1 difference. \(l_{FM-{\rm \; }mask}\) is responsible for comparing the real mask with the generated mask, while \(l_{FM-img}\) is responsible for comparing \(D_{img} \left(t,I\right)\) with \(D_{img} \left(t{'} ,I{'} \right)\).
The MS-COCO multi-target dataset is a large-scale dataset widely used in computer vision. The dataset can be used for tasks such as target detection, semantic segmentation, image generation, and keypoint detection. It contains more than 330K images, including more than 200K images with labels.
Frechette Initial Distance (FID), is a metric used to evaluate the quality of generated images. It measures the distance between two sets of images in the feature space to assess the fidelity and diversity of the generated images. The smaller the FID value of the generated false images, the closer the distribution between the generated false images and the real images in the feature space, i.e., the higher the quality of the generated images.
(2) Initial Score Indicator
Initial Score (IS) is a metric used to evaluate the quality of the generated images, which is often used to measure the diversity and realism of the generated images.IS quantitatively judges the quality of the generated images by combining the two aspects of image quality and image diversity.The higher the score of IS, the better the performance of the generated false images in terms of both realism and diversity.
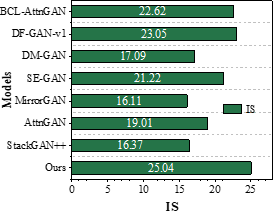
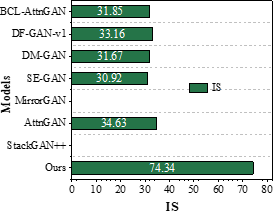
Numerical experimental quantitative analysis of the results for the text-image generation task. The performance of the model is compared with several text-generated image models on dataset CUB and dataset COCO through FID and IS metrics. The results of different models for generating image quality are shown in Figure 7a to 7d are the FID and IS results of the models on dataset CUB and dataset COCO.
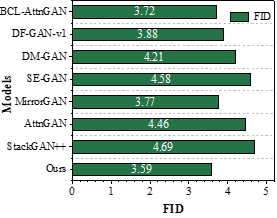
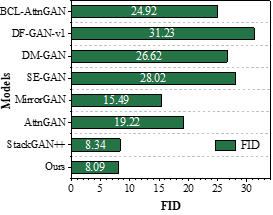
The comparison of the computational scores of the images generated by this paper’s lightweight generative adversarial network model based on the nonlocal attention mechanism and other models on the CUB dataset shows that the FID and IS values of this paper’s model are 3.59 and 25.04, respectively, and the IS metrics values of the images generated by this paper’s model are increased by 6.03, or 31.72%, when compared with the baseline model, AttnGAN. The value of FID metric decreased by 0.87 or 19.51%. From the comparison on the COCO dataset, it can be seen that the FID and IS values of this paper’s model are 8.09 and 74.34, respectively, and the values of IS metrics and FID metrics are increased and decreased by 115.67% and 57.91%, respectively, when compared with the baseline model AttnGAN. From a quantitative point of view, the effectiveness of the text-generated image model in this paper is proved.
The traditional skill of mango weaving is a kind of intangible cultural heritage with great local cultural characteristics, which faces mutation and extinction due to the development of the times and the influence of the market economy. This study analyzes the digital preservation and innovation of mang weaving based on AI technology. Combined with the LDA topic model, we mined the review texts of mango weaving products, in order to optimize the mango weaving production process after understanding the consumer feedback. Meanwhile, a text-generated image model based on non-local self-attention mechanism is constructed to assist the innovative design of mangwen.
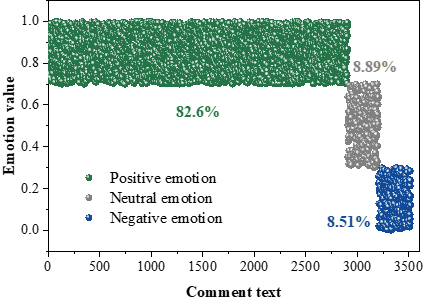
The review text of mango knitting is divided into five themes such as appearance design, quality workmanship, cultural connotation, product price, and social interaction, with probability values ranging from 0.181 to 0.227, among which the probability value of appearance design, which corresponds to the emotional value, is the largest, which indicates that consumers are more concerned about the appearance, quality, social attributes, and price of mango knitting. 82.6% of the review texts of mango knitting are positive emotions, and most consumers are more satisfied with mango knitting. The authors of mango knitting should pay attention to the emotional value of mango knitting, improve the quality of products, optimize the pricing strategy, and enhance the consumers’ experience needs and satisfaction, so as to achieve the sustainable development of mango knitting.
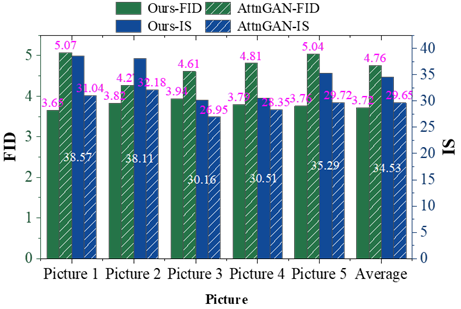
The output image FID values and IS values of the text generation image model in this paper outperform the comparison algorithm on different datasets and present better image quality. The average IS and FID values of the model-designed mango braid images are 3.72 and 34.53, which are 21.85% lower and 16.46% higher than the comparison model, respectively. The text-generated image model based on the nonlocal self-attention mechanism can be used in the R&D and design of mang weaving, which can inject new vitality into the innovation and development of mang weaving techniques.
Folk handicrafts not only reflect the process of cultural interpretation of a nation, but also the carrier of people’s personality traits and national cohesion. The conservation measures using digital intelligent technology can not only protect these precious folk arts, but also inherit and promote the folk culture and national spirit, which is worth people’s attention and exploration.
This research was supported by the 2024 School-Level Key Scientific Research Project of Guangxi Technological College of Machinery and Electricity, entitled “Research on the Digital Inheritance and Innovative Transformation of Guangxi’s Intangible Heritage Bamboo Weaving Technology in the Era of Digital Intelligence” (Project No.: 2024YKYS001).